- Introduction
- Background
- Patterns for Microfrontends
- A Framework for Microfrontends
- Points of Interest
- Further Reading
- Conclusion
- History
Introduction
Microfrontends are not a new thing, but certainly a recent trend. Coined in 2016, the pattern slowly gained popularity due to growing number of problems when developing large scale web apps. In this article, we'll go over the different patterns of creating microfrontends, their advantages and drawbacks, as well as implementation details and examples for each of the presented methods. I will also argue that microfrontends come with some inherited problems that may be solved by going even a step further - into a region that could be either called Modulith or Siteless UI depending on the point of view.
But let's go step by step. We start our journey with a historic background.
Background
When the web (i.e., HTTP as transport and HTML as representation) started, there was no notion of "design" or "layout". Instead, text documents have been exchanged. The introduction of the <img> tag changed that all. Together with <table> designers could declare war on good taste. Nevertheless, one problem arises quite quickly: How is it possible to share a common layout across multiple sites? For this purpose, two solutions have been proposed:
- Use a program to dynamically generate the HTML (slowish, but okay - especially with the powerful capabilities behind the CGI standard)
- Use mechanisms already integrated into the web server to replace common parts with other parts.
While the former lead to C and Perl web servers, which became PHP and Java then converted to C# and Ruby, before finally emerging at Elixir and Node.js, the latter wasn't really after 2002. The web 2.0 also demanded more sophisticated tools, which is why server-side rendering using full-blown applications dominated for quite a while.
Until Netflix came and told everyone to make smaller services to make cloud vendors rich. Ironically, while Netflix would be ready for their own data centers, they are still massively coupled to cloud vendors such as AWS, which also hosts most of the competition including Amazon Prime Video.
Patterns for Microfrontends
In the following, we'll look at some of the patterns that are possible for actually realizing a microfrontend architecture. We'll see that "it depends" is in fact the right answer when somebody asks: "what is the right way to implement microfrontends?". It very much depends on what we are after.
Each section contains a bit of an example code and a very simple snippet (sometimes using a framework) to realize that pattern for a proof of concept or even an MVP. At the end, I try to provide a small summary to indicate the target audience according to my personal feelings.
Regardless of the pattern you choose, when integrating separate projects, keeping a consistent UI is always a challenge. Use tools like Bit (Github) to share and collaborate on UI components across your different microservices.
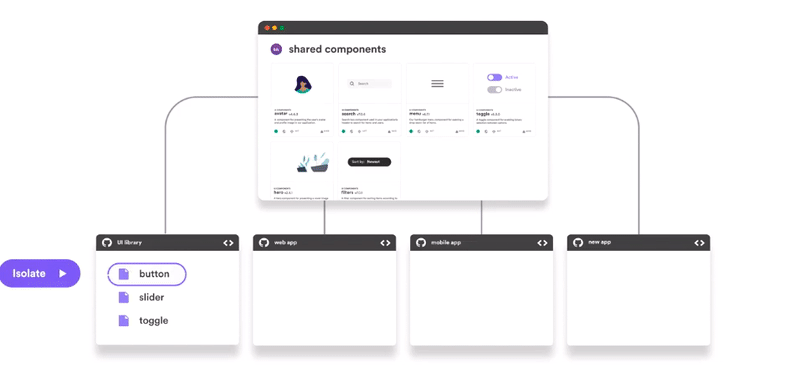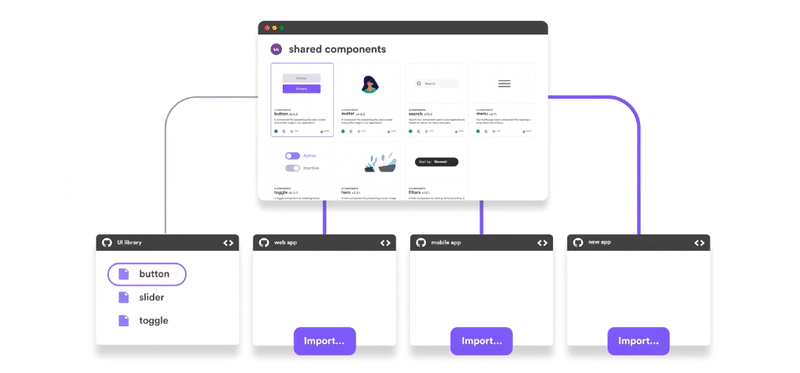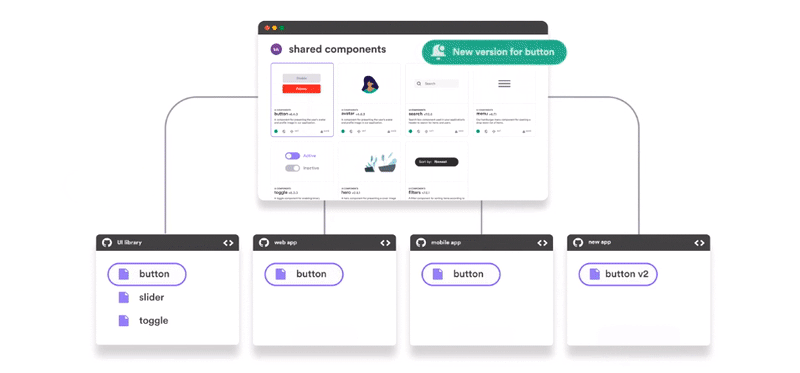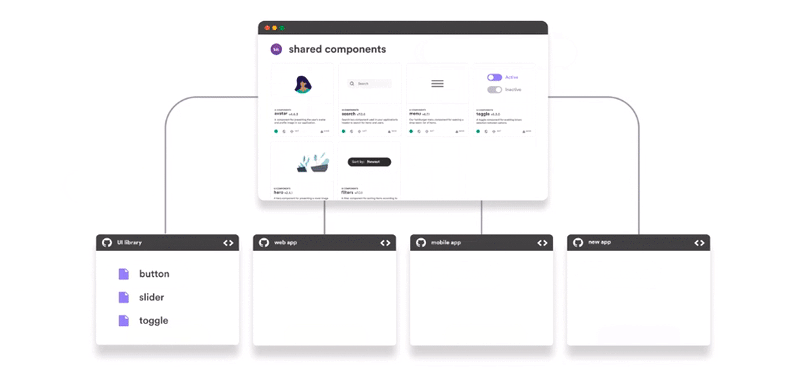
The Web Approach
The most simple method of implementing microfrontends is to deploy a set of small websites (ideally just a single page), which are just linked together. The user goes from website to website by using the links leading to the different servers providing the content.
To keep the layout consistent, a pattern library may be used on the server. Each team can implement the server-side rendering as they desire. The pattern library must also be usable on the different platforms.

Using the web approach can be as simple as deploying static sites to a server. This could be done with a Docker image as follows:
FROM nginx:stable
COPY ./dist/ /var/www
COPY ./nginx.conf /etc/nginx/conf.d/default.conf
CMD ["nginx -g 'daemon off;'"]
Obviously, we are not restricted to use a static site. We can apply server-side rendering, too. Changing the nginx base image to, e.g., ASP.NET Core allows us to use ASP.NET Core for generating the page. But how is this different to the frontend monolith? In this scenario, we would, e.g., take a given microservice exposed via a web API (i.e., returning something like JSON) and change it to return rendered HTML instead.
Logically, microfrontends in this world are nothing more than a different way of representing our API. Instead of returning "naked" data, we generate the view already.
In this space, we find the following solutions:
What are the pros and cons of this approach?
- Pro: Completely isolated
- Pro: Most flexible approach
- Pro: Least complicated approach
- Con: Infrastructure overhead
- Con: Inconsistent user experience
- Con: Internal URLs exposed to outside
Server-Side Composition
This is the true microfrontend approach. Why? As we have seen, microfrontends have been supposed to be run server-side. As such, the whole approach works independently for sure. When we have a dedicated server for each small frontend snippet, we may really call this microfrontend.
In diagrammatic form, we may end up with a sketch like below:
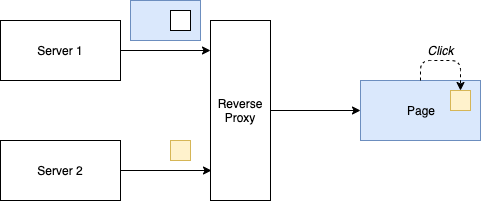
The complexity for this solution lies totally in the reverse proxy layer. How the different smaller sites are combined into one site can be tricky. Especially things like caching rules, tracking, and other tricky bits will bite us at night.
In some sense, this adds a kind of gateway layer to the first approach. The reverse proxy combines different sources into a single delivery. While the tricky bits certainly need to (and can) be solved somehow.
http {
server {
listen 80;
server_name www.example.com;
location /api/ {
proxy_pass http://api-svc:8000/api;
}
location /web/admin {
proxy_pass http://admin-svc:8080/web/admin;
}
location /web/notifications {
proxy_pass http://public-svc:8080/web/notifications;
}
location / {
proxy_pass /;
}
}
}
A little bit more powerful would be something like using Varnish Reverse Proxy.
In addition, we find that this is also a perfect use case for ESI (abbr. Edge-Side Includes) - which is the (much more flexible) successor to the historic Server-Side Includes (SSI).
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Demo</title>
</head>
<body>
<esi:include src="http://header-service.example.com/" />
<esi:include src="http://checkout-service.example.com/" />
<esi:include
src="http://navigator-service.example.com/"
alt="http://backup-service.example.com/"
/>
<esi:include src="http://footer-service.example.com/" />
</body>
</html>
A similar setup can be seen with the Tailor backend service, which is a part of Project Mosaic.
In this space, we find the following solutions:
What are the pros and cons of this approach?
- Pro: Completely isolated
- Pro: Looks embedded to user
- Pro: Very flexible approach
- Con: Enforces coupling between the components
- Con: Infrastructure complexity
- Con: Inconsistent user experience
Client-Side Composition
At this point, one may be wondering: Do we need the reverse proxy? As this is a backend component, we may want to avoid this altogether. The solution is client-side composition. In the simplest form, this can be implemented with the use of <iframe> elements. Communication between the different parts is done via the postMessage method.
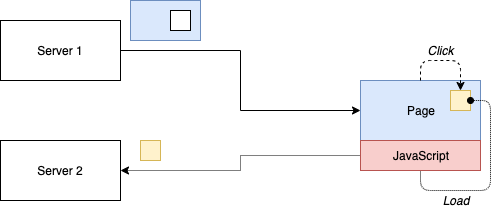
Note: The JavaScript part may be replaced with "browser" in case of an <iframe>. In this case, the potential interactivity is certainly different.
As already suggested by the name, this pattern tries to avoid the infrastructure overhead coming with a reverse proxy. Instead, since microfrontends already contain the term "frontend" the whole rendering is left to the client. The advantage is that starting with this pattern serverless may be possible. In the end, the whole UI could be uploaded to, e.g., a GitHub pages repository and everything just works.
As outlined, the composition can be done with quite simple methods, e.g., just an <iframe>. One of the major pain points, however, is how such integrations will look to the end user. The duplication in terms of resource needs is also quite substantial. A mix with pattern 1 is definitely possible, where the different parts are being placed on independently operated web servers.
Nevertheless, in this pattern knowledge is required again - so component 1 already knows that component 2 exists and needs to be used. Potentially, it even needs to know how to use it.
Considering the following parent (i.e., delivered application or website):
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Microfrontends Shell</title>
</head>
<body>
<h1>Parent</h1>
<p><button id="message_button">Send message to child</button></p>
<div id="results"></div>
<script>
const iframeSource = "https://example.com/iframe.html";
const iframe = document.createElement("iframe");
const messageButton = document.querySelector("#message_button");
const results = document.querySelector("#results");
iframe.setAttribute("src", iframeSource);
iframe.style.width = "450px";
iframe.style.height = "200px";
document.body.appendChild(iframe);
function sendMessage(msg) {
iframe.contentWindow.postMessage(msg, "*");
}
messageButton.addEventListener("click", function(e) {
sendMessage(Math.random().toString());
});
window.addEventListener("message", function(e) {
results.innerHTML = e.data;
});
</script>
</body>
</html>
We can write a page that enables the direct communication path:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Microfrontend</title>
</head>
<body>
<h1>Child</h1>
<p><button id="message_button">Send message to parent</button></p>
<div id="results"></div>
<script>
const results = document.querySelector("#results");
const messageButton = document.querySelector("#message_button");
function sendMessage(msg) {
window.parent.postMessage(msg, "*");
}
window.addEventListener("message", function(e) {
results.innerHTML = e.data;
});
messageButton.addEventListener("click", function(e) {
sendMessage(Math.random().toString());
});
</script>
</body>
</html>
If we do not consider frames an option, we could also go for web components. Here, communication could be done via the DOM by using custom events. However, already at this point in time, it may make sense to consider client-side rendering instead of client-side composition; as rendering implies the need for a JavaScript client (which aligns with the web component approach).
In this space, we find the following solutions:
What are the pros and cons of this approach?
- Pro: Completely isolated
- Pro: Looks embedded to user
- Pro: Serverless possible
- Con: Enforces coupling between the components
- Con: Inconsistent user experience
- Con: May require JavaScript / no seamless integration
Client-Side Rendering
While client-side composition may work without JavaScript (e.g., only using frames that do not rely on communication with the parent or each other), client-side rendering will fail without JavaScript. In this space, we already start creating a framework in the composing application. This framework has to be respected by all microfrontends brought in. At least, they need to use it for being mounted properly.
The pattern looks as follows:
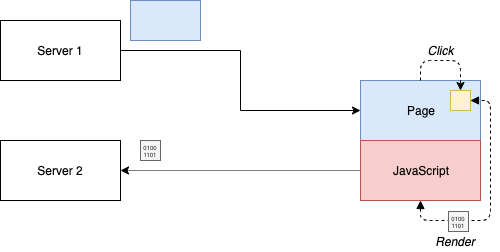
Quite close to the client-side composition, right? In this case, the JavaScript part may not be replaced. The important difference is that server-side rendering is in general off the table. Instead, pieces of data are exchanged, which are then transformed into a view.
Depending on the designed or used framework, the pieces of data may determine the location, point in time, and interactivity of the rendered fragment. Achieving a high degree of interactivity is no problem with this pattern.
In this space, we find the following solutions:
What are the pros and cons of this approach?
- Pro: Enforces separation of concerns
- Pro: Provides loose coupling of the components
- Pro: Looks embedded to the user
- Con: Requires more logic in the client
- Con: Inconsistent user experience
- Con: Requires JavaScript
SPA Composition
Why should we stop at client-side rendering using a single technology? Why not just obtain a JavaScript file and run it besides all the other JavaScript files? The benefit of this is the potential use of multiple technologies side-by-side.
It is up for debate if running multiple technologies (independent if it's in the backend or the frontend - granted, in the backend, it may be more "acceptable") is a good thing or something to avoid, however, there are scenarios where multiple technologies need to work together.
From the top of my head:
- Migration scenarios
- Support of a specific third-party technology
- Political issues
- Team constraints
Either way, the emerged pattern could be drawn as below:
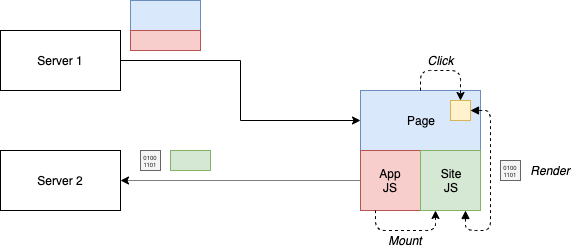
So what is going on here? In this case, delivering just some JavaScript with the app shell is no longer optional - instead, we need to deliver a framework that is capable of orchestrating the microfrontends.
The orchestration of the different modules boils down to the management of a lifecycle: mounting, running, unmounting. The different modules can be taken from independently running servers, however, their location must be already known in the application shell.
Implementing such a framework requires at least some configuration, e.g., a map of the scripts to include:
const scripts = [
'https://example.com/script1.js',
'https://example.com/script2.js',
];
const registrations = {};
function activityCheck(name) {
const current = location.hash;
const registration = registrations[name];
if (registration) {
if (registration.activity(current) !== registration.active) {
if (registration.active) {
registration.lifecycle.unmount();
} else {
registration.lifecycle.mount();
}
registration.active = !registration.active;
}
}
}
window.addEventListener('hashchange', function () {
Object.keys(registrations).forEach(activityCheck);
});
window.registerApp = function(name, activity, lifecycle) {
registrations[name] = {
activity,
lifecycle,
active: false,
};
activityCheck(name);
}
scripts.forEach(src => {
const script = document.createElement('script');
script.src = src;
document.body.appendChild(script);
});
The lifecycle management may be more complicated than the script above. Thus a module for such a composition needs to come with some structure applied - at least an exported mount and unmount function.
In this space, we find the following solutions:
What are the pros and cons of this approach?
- Pro: Enforces separation of concerns
- Pro: Gives developers much freedom
- Pro: Looks embedded to the user
- Con: Enforces duplication and overhead
- Con: Inconsistent user experience
- Con: Requires JavaScript
Siteless UIs
This topic deserves its own article, but since we are listing all the patterns, I don't want to omit it here. Taking the approach of SPA composition, all we miss is a decoupling (or independent centralization) of the script sources from the services, as well as a shared runtime.
Both things are done for a reason:
- The decoupling makes sure that UI and service responsibilities are not mixed up; this also enables serverless computing
- The shared runtime is the cure for the resource intense composition given by the previous pattern.
Both things combined yield benefits to the frontend as "serverless functions" did for the backend. They also come with similar challenges:
- The runtime cannot be just updated - it must stay / remain consistent with the modules.
- Debugging or running the modules locally require an emulator of the runtime.
- Not all technologies may be supported equally.
The diagram for siteless UIs looks as follows:
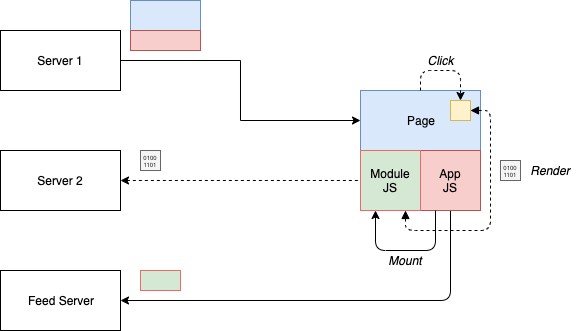
The main advantage of this design is that sharing of useful or common resources is supported. Sharing a pattern library makes a lot of sense.
For pattern libraries, tools like Bit help not only with the set up, but even to collaborate on components with other developers or teams. This makes it much easier to maintain a consistent UI across microfrontends, without investing time and effort on building and maintaining a UI component library.
All in all, the architecture diagram looks quite similar to the SPA composition mentioned earlier. However, the feed service and the coupling to a runtime bring additional benefits (and challenges to be solved by any framework in that space). The big advantage is that once these challenges are cracked, the development experience is supposed to be excellent. The user experience can be fully customized, treating the modules as flexible opt-in pieces of functionality. A clear separation between feature (the respective implementation) and permission (the right to access the feature) is thus possible.
One of the easiest implementations of this pattern is the following:
// app-shell/main.js
window.app = {
registerPage(url, cb) {}
// ...
};
showLoading();
fetch("https://feed.piral.io/api/v1/pilet/sample")
.then(res => res.json())
.then(body =>
Promise.all(
body.items.map(
item =>
new Promise(resolve => {
const script = document.createElement("script");
script.src = item.link;
script.onload = resolve;
document.body.appendChild(script);
})
)
)
)
.catch(err => console.error(err))
.then(() => hideLoading());
// module/index.jsx
import * as React from "react";
import { render } from "react-dom";
import { Page } from "./Page";
if (window.app !== undefined) {
window.app.registerPage("/sample", element => {
render(<Page />, element);
});
}
This uses a global variable to share the API from the app shell. However, we already see several challenges using this approach:
- What if one module crashes?
- How to share dependencies (to avoid bundling them with each module, as shown in the simple implementation)?
- How to get proper typing?
- How is this being debugged?
- How is proper routing done?
Implementing all of these features is a topic of its own. Regarding the debugging, we should follow the same approach as all the serverless frameworks (e.g., AWS Lambda, Azure Functions) do. We should just ship an emulator that behaves like the real thing later on; except that it is running locally and works offline.
In this space, we find the following solutions:
What are the pros and cons of this approach?
- Pro: Enforces separation of concerns
- Pro: Supports sharing of resources to avoid overhead
- Pro: Consistent and embedded user experience
- Con: Strict dependency management for shared resources necessary
- Con: Requires another piece of (potentially managed) infrastructure
- Con: Requires JavaScript
A Framework for Microfrontends
Finally, we should have a look at how one of the provided frameworks can be used to implement microfrontends. We go for Piral as this is the one I'm most familiar with.
In the following, we approach the problem from two sides. First, we start with a module (i.e., microfrontend) in this context. Then, we'll walk over creating an app shell.
For the module, we use my Mario5 toy project. This is a project that started several years ago with a JavaScript implementation of Super Mario called "Mario5". It was followed up by a TypeScript tutorial / rewrite named "Mario5TS", which has been kept up-to-date since then.
For the app shell, we utilize the sample Piral instance. This one shows all concepts in one sweep. It's also always kept up-to-date.
Let's start with a module, which in the Piral framework is called a pilet. At its core, a pilet has a JavaScript root module which is usually located in src/index.tsx.
A Pilet
Starting with an empty pilet gives us the following root module:
import { PiletApi } from "sample-piral";
export function setup(app: PiletApi) {}
We need to export a specially named function called setup. This one will be used later to integrate the specific parts of our application.
Using React, we could, for instance, register a menu item or a tile to be always displayed:
import "./Styles/tile.scss";
import * as React from "react";
import { Link } from "react-router-dom";
import { PiletApi } from "sample-piral";
export function setup(app: PiletApi) {
app.registerMenu(() => <Link to="/mario5">Mario 5</Link>);
app.registerTile(
() => (
<Link to="/mario5" className="mario-tile">
Mario5
</Link>
),
{
initialColumns: 2,
initialRows: 2
}
);
}
Since our tile requires some styling, we also add a stylesheet to our pilet. Great, so far so good. All the directly included resources will always be available on the app shell.
Now it's time to also integrate the game itself. We decide to put it in a dedicated page, even though a modal dialog may also be cool. All the code sits in mario.ts and works against the standard DOM - no React yet.
As React also supports manipulation of hosted nodes, we use a reference hook to attach the game.
import "./Styles/tile.scss";
import * as React from "react";
import { Link } from "react-router-dom";
import { PiletApi } from "sample-piral";
import { appendMarioTo } from "./mario";
export function setup(app: PiletApi) {
app.registerMenu(() => <Link to="/mario5">Mario 5</Link>);
app.registerTile(
() => (
<Link to="/mario5" className="mario-tile">
Mario5
</Link>
),
{
initialColumns: 2,
initialRows: 2
}
);
app.registerPage("/mario5", () => {
const host = React.useRef();
React.useEffect(() => {
const gamePromise = appendMarioTo(host.current, {
sound: true
});
gamePromise.then(game => game.start());
return () => gamePromise.then(game => game.pause());
});
return <div ref={host} />;
});
}
Theoretically, we could also add further functionality such as resuming the game or lazy loading the side-bundle containing the game. Right now, only sounds are lazy loaded through calls to the import() function.
Starting the pilet will be done via...
npm start
...which uses the Piral CLI under the hood. The Piral CLI is always installed locally, but could also be installed globally to get commands such as pilet debug directly available in the command line.
Building the pilet can also be done with the local installation.
npm run build-pilet
The App Shell
Now it's time to create an app shell. Usually, we would already have an app shell (e.g., the previous pilet was already created for the sample app shell), but in my opinion, it's more important to see how development of a module goes.
Creating an app shell with Piral is as simple as installing piral. To make it even more simple, the Piral CLI also supports scaffolding of a new app shell.
Either way, we will most likely end up with something like this:
import * as React from "react";
import { render } from "react-dom";
import { createInstance, Piral, Dashboard } from "piral";
import { Layout, Loader } from "./layout";
const instance = createInstance({
requestPilets() {
return fetch("https://feed.piral.io/api/v1/pilet/sample")
.then(res => res.json())
.then(res => res.items);
}
});
const app = (
<Piral instance={instance}>
<SetComponent name="LoadingIndicator" component={Loader} />
<SetComponent name="Layout" component={Layout} />
<SetRoute path="/" component={Dashboard} />
</Piral>
);
render(app, document.querySelector("#app"));
Here, we do three things:
- We set up all the imports and libraries
- We create the Piral instance; supplying all functional options (most importantly declaring where the pilets come from)
- We render the app shell using components and a custom layout that we defined
The actual rendering is done from React.
Building the app shell is straight forward - in the end, it's a standard bundler (Parcel) to process the whole application. The output is a folder containing all files to be placed on a webserver or static storage.
Points of Interest
Coining the term "Siteless UI" potentially requires a bit of explanation. I'll try to start with the name first: As seen, it is a direct reference to "Serverless Computing". While serverless may also be a good term for the used technology, it may also be misleading and wrong. UIs can generally be deployed on serverless infrastructures (e.g., Amazon S3, Azure Blob Storage, Dropbox). This is one of the benefits of "rendering the UI on the client" instead of doing server-side rendering. However, I wanted to follow the approach "having an UI that cannot live without a host" kind a thing. Same as with serverless functions, which require a runtime sitting somewhere and could not start otherwise.
Let's compare the similarities. First, let's start of with the conjunction that microfrontends should be to frontend UIs what microservices have been to backend services. In this case, we should have:
- can start standalone
- provide independent URLs
- have independent lifetime (startup, recycle, shutdown)
- do independent deployments
- define an independent user / state management
- run as a dedicated webserver somewhere (e.g., as a docker image)
- if combined, we use a gateway-like structure
Great, certainly some things that apply here and there, however, note that some of this contradicts with SPA composition and, as a result, with siteless UIs, too.
Now let's compare this to an analogy that we can do if the conjecture changes to: siteless UIs should be to frontend UIs what serverless functions have been to backend services. In this case, we have:
- require a runtime to start
- provide URLs within the environment given by the runtime
- are coupled to the lifetime defined by the runtime
- do independent deployments
- defined partially independent, partially shared (but controlled / isolated) user / state management
- run on a non-operated infrastructure somewhere else (e.g., on the client)
If you agree that this reads like a perfect analogy - awesome! If not, please provide your points in the comments blow. I'll still try to see where this is going and if this seems like a great idea to follow. Much appreciated!
Further Reading
The following posts and articles may be useful to get a complete picture:
- Bits and Pieces, 11/2019
- dev.to, 11/2019
- LogRocket, 02/2019
- Micro frontends—a microservice approach to front-end web development
- Micro Front-Ends: Available Solutions
- Exploring micro-frontends
- 6 micro-front-end types in direct comparison: These are the pros and cons (translated)
Conclusion
Microfrontends are not for everyone. Hell, they are not even for every problem. But what technology is? They certainly fill a spot. Depending on the specific problem, one of the patterns may be applicable. It's great that we have many diverse and fruitful solutions available. Now the only problem is to choose - and choose wisely!
History
- v1.0.0 | Initial release | 20.11.2019
- v1.1.0 | Added more info about Bit | 22.11.2019
- v1.2.0 | Added ToC | 25.11.2019