
Introduction
Last year Microsoft decided to give its Team Foundation Service, Visual Studio Online, Visual Studio Team Services a new branding: Azure DevOps was born. One of the great marketing tools here was the introduction of some subproducts (formerly known as functionalities of the real product) like Azure Boards (managing issues) or Azure Repos (source code repositories). Another one was Azure Pipelines, which consists of build jobs and release definitions. This is the CI/CD solution Microsoft offers as a service.
A real cool pitch for using Azure Pipelines is the "use free" advertisement. In short, it allows us to use up to 10 parallel running build jobs for our own projects. I guess I don't have to tell you that this is a quite good offer. Indeed, there are many CI/CD providers on the market (offering a free service for open-source projects), but none of them is giving us (for non-open-source-projects) that kind of firepower.

To make the free-to-use pitch even better Microsoft embedded Azure Pipelines quite well in one of their latest (and from their strategy point of view most precious) acquisitions: GitHub.
In this article I want to introduce you how the Azure Pipelines - GitHub integration works and what you can do with it. We will play with three kind of different scenarios and see how some edge cases can be solved. This article is not an introduction to Azure Pipelines, nor to GitHub.
Background
I've been using TFS for a quite long time. When VSO came up (the first product to include the new Monaco editor, which later became the heart of VS Code, which is the editor eating the world right now) I was instantly sold. Nevertheless, it was very TFS-heavy from a user perspective and maybe not placed so well on the market. In the end it failed to deliver.
Microsoft was trying a lot to improve the adoption of this product, but was eventually falling behind the competition. In the end with VSTS (Visual Studio Team Services) Microsoft (from my point of view) achieved a turn around. Even though the product was in every area one step behind a competitor, overall it was certainly (maybe next to GitLab) the most well-rounded and usable solution on the market. I used it heavily in two companies where I was responsible for the architecture of a large scale project and the product itself delivered. Yes, there have been cases where it felt not like we have been empowered by the tool but overall it delivered. With the introduction of Azure DevOps the design and the overall experience improved even more.
I host quite a lot of project on GitHub (I would not consider myself a power user, even though I guess I am using it quite regularly / heavily) and I almost always try to bring in some CI/CD to avoid having to know how to release something in the future. After all, just pushing to master (or making a PR there with an eventual review) should be sufficient to create a new release. Previously, I used things like Travis CI (mostly Node.js / JS projects) and AppVeyor (mostly for .NET / C# projects) to bring open-source projects to sanity. With Azure Pipelines a new charming way was offered so I could not resist.
Integrating Azure Pipelines in GitHub
There are two major ways to integrate Azure Pipelines in GitHub (or vice versa depending on your point of view). The first way is via GitHub. In the market place we find Azure Pipelines (search for it!). We then have to give this application access to our repositories. Don't worry you can actually revoke any access. New organizations are not automatically given access, so you will eventually need to visit these OAuth settings anyway, but we come to that in a bit.
This is how the GitHub market place may look for you.

While the first way may be quite straight forward for a first-time use it is nothing that scales. Once the application (Azure Pipelines) has been granted access you cannot go on with this way. Hence the second way (which works initially, but also for any subsequent use) is my preference.
Let's log in to Azure DevOps to create a new pipeline. Let's start with a blank pipeline. In the first question we can already choose GitHub as a source for the repository.

Going on with this we see that an OAuth access token needs to be provided. If this has not been we will now grant access to the Azure Pipelines application - problem solved! At least until you will eventually want to set up a repository from an organization you belong to. What if you do not see the repository - or any repository from this organization? Well, time to see if the application (i.e., Azure Pipelines) is actually allowed to access information from this organization. This can be done via:
- In the user menu "Settings"
- Select "Application" in the menu on the left
- "Authorized OAuth Apps"
- Clicking on Azure Pipelines shows the detailed security settings
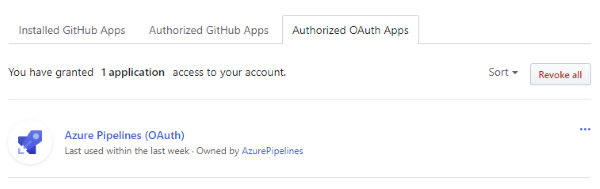
This way we can control what organizations can be accessed by the application.
Once everything is set up we can create a small pipeline and see if it builds (and deploys!) correctly.
If we did everything correctly, we can always grab a nice badge for our repositories. This looks as follows:
![]()
To get the badge look for your Azure Pipeline in Azure DevOps and press the "..." to see additional options (such as edit). In there the "Status Badge" is marked. Showing you the exact code (HTML or Markdown) is useless as the most important information is the Pipeline id, which you need to get anyway (so you can instead also get the full code directly from Azure DevOps).
YAML or not to YAML?
When we used VSTS (the predecessor of Azure DevOps) heavily we first needed to take some spins to end up with a good system for creating build jobs. The main problem was that a build job had to be created graphically. Talking about a backend with 100+ services (each service in its own repository) plus tooling, libraries, and clients it can easily be seen that such a process does not scale. Editing a build process graphically looks similar to the screen below:
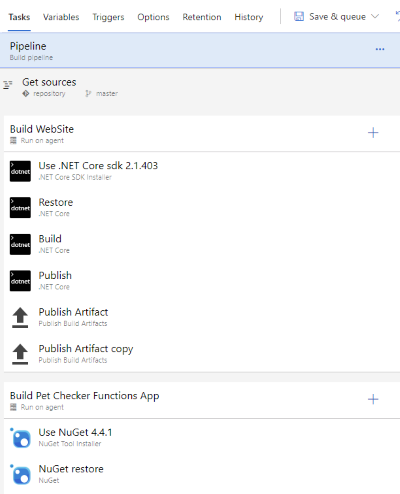
Yes, there is something called a "task group", which is a way to (graphically) make a list of steps re-usable. And indeed, this is what we used to circumvent the re-usability problem a bit. But in the end, you'll have a system of 15+ task groups that have dependencies to each other and take some inputs which may also be similar. Again, changing something (e.g., due to a convention change) could result in needing to go over many places. But that is not even the biggest problem.
The biggest problem for using the graphical step editor is that the build job is placed on a separate location to the source code its based on. As a consequence, we have no correlation between a change in the build job and the source code. Also the responsibility is not really clear.
With Azure DevOps a (well known) solution was introduced: A YAML file can be used to specify how the whole process should look like.
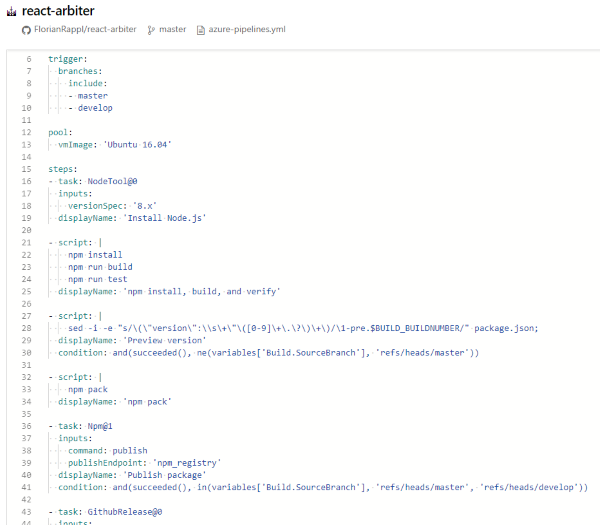
Its important to understand that the two approaches are mutually exclusive. Even though the graphical representation gives us the possibility to be serialized into a YAML it is still hosted in some unknown location, while a real YAML file would be hosted in the repository itself.
So which one should we pick? Personally, I tend to use the YAML representation if
- the build job is really simple
- others (maintainers) need to see / change the build job
- the project consists of many repositories with similar build jobs (tooling required)
On the other hand, if I have a complicated pipeline in front of me I would love to start with graphical editor first. Also if the exact build job should be hidden (or is not so interesting) I avoid adding a YAML file to the repository.
If the situation is unclear my recommendation is to start with the graphical editor and then go the YAML once necessary. This is the easy direction and should always be possible.
Deploy GitHub Pages with Azure Pipelines
One of the things I want to do with Azure Pipelines is to automate the deployment of a web app to GitHub pages. Right now this web app needs to be deployed manually, i.e., from a dev's machine using the command line via npm run deploy.
To have the publish process (i.e., build and deploy) of this React Single-Page Application (SPA) automated will be our goal for this section. While the start (i.e., integrating the basic pipeline) in Azure Pipelines is ultra simple (I would even consider calling it trivial) custom tasks seem to be a little bit more problematic. In this case I faced an issue with just calling the gh-pages command that will essentially just do a git push. This is called a repush and as we will see, it is even more problematic is the target of the repush is the same branch as the one we currently build from. But more on that later.
The solution to overcome all problems incl. "invalid device or username" to access GitHub for pushing, "who are you" for using Git, or "the password is displayed in the logs" is realized in 3 simple steps.
Step 1 - Get a GitHub PAT
Go to your GitHub settings and enter the developer settings tab. In there we have the personal access tokens (PATs). These are quite heavy security keys that will have direct access to your account. Treat them very carefully. However, they offer certain benefits:
- They can be revoked
- They can be targetted (at different APIs) / equipped with different claims
- They can be prolonged / extended
- They can expire
We should create a new token that is only capable of accessing a certain repository (pull, push, ...). Copy the value and use it in the next step.
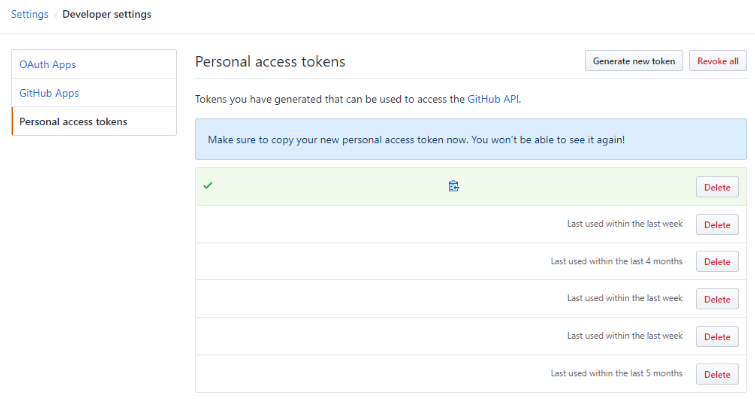
Step 2 - Variables
Open the Azure Pipeline in the Azure DevOps page. Go to variables and create a new variable (e.g., called github_pat). Make sure to check the secret check box. The value of this environment variable is the one we have extracted in the first step (the PAT).
Step 3 - Pipeline YAML
Now we need to adjust the azure-pipelines.yml file. Let's assume we started with a basic Node.js build process (since we have a React SPA). We need to transform it from the basic version to this:
pool:
vmImage: 'Ubuntu 16.04'
trigger:
- source
steps:
- checkout: self
persistCredentials: true
- task: NodeTool@0
inputs:
versionSpec: '8.x'
displayName: 'Install Node.js'
- script: |
git config user.email "yourmail"
git config user.name "yourname"
npm install
npm run deploy -- -r https://$(github_pat)@github.com/yourrepo.git
displayName: 'npm install and build'
What does it do? Well, most importantly we use an explicit URL for our repository located at GitHub. This URL contains the access information in form of the PAT. The PAT is received from the environment variable and won't be shown in any logs.
In order to use Git in the deploy script (which is only using gh-pages underneath, hence the -r flag) we need to set up git locally. The relevant lines are the ones that call git config. Make sure to enter your details there.
Monorepo Workflows based on Lerna with Azure Pipelines
I just started using a monorepo for a larger JavaScript project we've started at work. So far this is working fine, but the CI/CD was giving me problems. If you want to know a bit about the background / workflow details feel free to check out my blog. In short, we choose the standard tool Lerna to manage our monorepo, but we deviated from the official workflow a bit (e.g., not using conventional changelogs, but rather explicit changelogs with full control over the released version number).
To make the monorepo setup with Lerna work from the CI/CD provider (in this case Azure DevOps) we need to refine our pipeline a bit. While the Lerna commands will certainly work we still need to put in a bit of work on the actual CI/CD pipeline.
Let's first see what we actually want to have. The following diagram shows our wanted process:
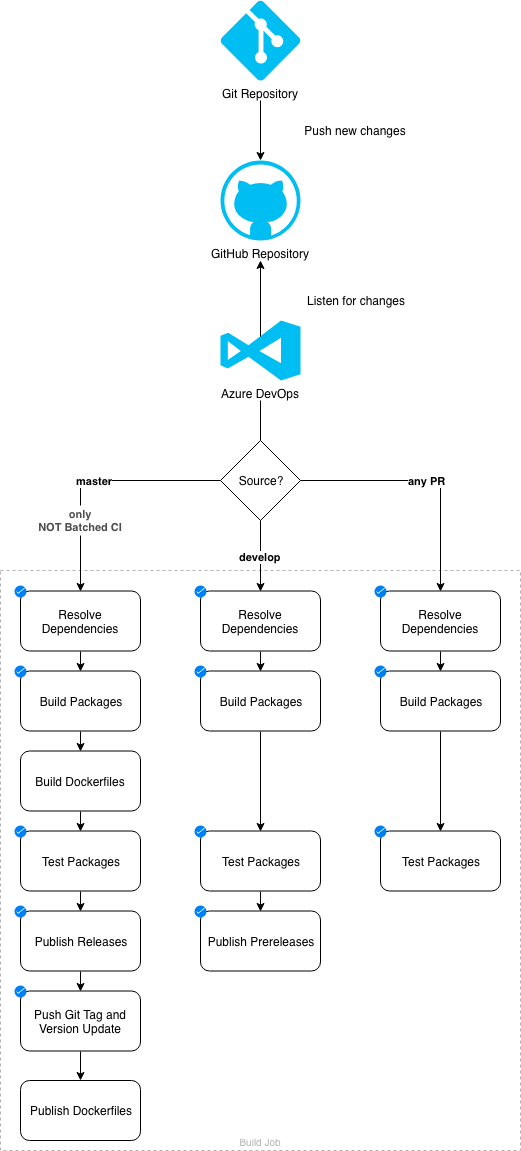
This is a fairly standard setup - we want build validation (for pull requests) + preview releases (for changes in the develop branch) + releases (for changes in the master branch). However, note that in the release pipeline we also do a pushback to reflect back changes in the source code (all packages have been version updated) and have the latest release tagged on GitHub.
We start with a Git repository that is mirrored at GitHub. The GitHub repository contains some hooks that trigger a process at Azure DevOps. From there we need to distinguish between three potential cases:
- We have a pull request validation (only build and test)
- We have a change to develop (build, test, and if all goes well publish a preview of the available packages)
- We have a change in master (build, test, and if all goes well publish the full thing, plus push back changes made to package.json files and a new Git tag)
Since we do a push back we will have another change in master. This would trigger yet another build so we need to be rather protective. Luckily, Azure DevOps allows us to batch changes during a build (i.e., not having another build at the same time). Batched changes get a special flag (i.e., reason), which can be handled with a precondition. Thus, if we have batched changes from master, we can just ignore them as push-back changes.
In order to make proper push back changes we need the Git credentials (like in the previous section with a release to GitHub pages). For this we should create personal access token (short PAT) in GitHub. The PAT is really security sensitive - do only copy it once, place it in the pipeline's variables as a secret and never look back! If in doubt, generate a new PAT and replace the old value. Never reuse a PAT, otherwise you will get two problems: 1) not knowing what PAT may have been leaked and 2) not knowing what is affected when the PAT is expired / revoked.
Placing the GitHub PAT into the variables looks like the following excerpt:
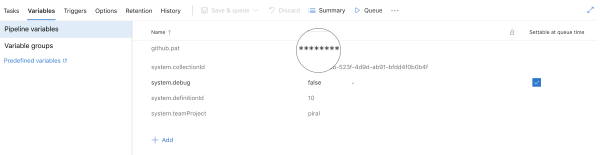
Finally, with this variable we can introduce a new step in our pipeline. The important part that this step is required before any push back.
This can look as follows (in contrast to the GitHub pages examples where we used the script in a YAML):
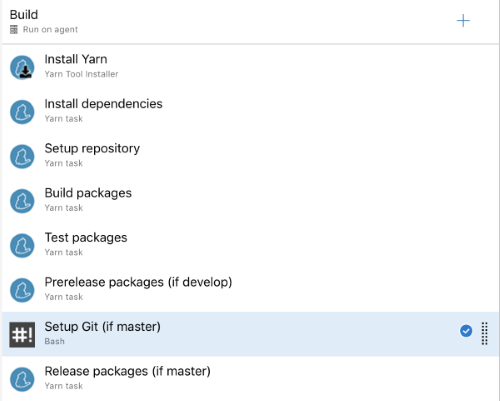
What we do in that step is to check out the master branch (Lerna wants to see this instead of the exact commit SHA; actually, this justifies to place the given step as early as possible in the pipeline, but these are details...) and modify the repository URL (origin) to contain the PAT. We need to do this magic as Lerna does not accept an override of the remote URL (only a different remote). Additionally, we also configure Git with some user to avoid any error message and make it clear that the commit has been done by our CI system.
Make sure to replace all the placeholder names in the following snippet!
git config --global user.email "your@bot"
git config --global user.name "Your Bot"
git remote rm origin
git remote add origin https://$gt@github.com/orga/repo.git
git fetch origin
git checkout master
Points of Interest
If you like this article let me know. Due to my experience with Azure DevOps I have a lot of other topics I can write about (e.g., a bag of tricks like how to (ab) use Azure Pipelines for saving server costs). Anything particular you are interested in? Just let me know! Any comment / remark appreciated.
History
- v1.0.0 | Initial Release | 26.02.2019