
Contents
- Introduction
- Background
- Advantages of Grunt
- Why Gulp?
- Getting started
- Using the code
- Points of Interest
- History
Introduction
Finally 2015 has arrived. This is a year that will bring even more wonderful advances in technology. It is also the year where Visual Studio 2015 will be released. Another year, another version of Visual Studio most people would say. But there is more behind it! First of all it will be the first version that ships with the .NET Compiler Platform ("Roslyn"). This does not only include a new version of the C# (and VB) programming language, but also innovative tools that build upon the concept of a compiler-as-a-service. And then this will also influence other products ...
One of these products is ASP.NET. The framework has been re-written from the ground-up. It has been decoupled from the System.Web dependency and is ready to go cross-platform without much dazzle. It also features compile-as-you-go without touching the HDD with binaries. This is all due to Roslyn and countless efforts in improving the web framework. No matter if you want to do webforms, MVC or just a lightweight web API - the new ASP.NET is certainly something to love.
This change does not only have consequences for back-end development, but also for front-end enthusiasts. In ASP.NET MVC 4 the team included features such as bundling. The idea was simple: combine (and minify, if appropriate) contents with certain rules. It all got more complicated with special files in higher languages, such as SASS or TypeScript. There the usual solution was to compile to the lower variant (CSS or JavaScript) when the source was changed. The compiled file has then triggered the change of the distributed bundle.
A few years later this seems still to work, but it is far away from the work done by pure front-end web developers. Here we do setup a build process that basically acts like makefiles in the old days. We declare what we have and what we want to do. In the end we have a result that could be deployed. Once reached the deployment we need the run the makefile to get an updated version. There is no intelligent program that checks against changes all the time. No file watcher needed.
Therefore ASP.NET 6 will remove bundling and related features and rely on a front-end build process. Makefiles are possible, but why not start playing with the cool kids right away? Therefore ASP.NET team included two important build systems out-of-the-box (with IDE integration): The established Grunt task runner and its newer rival Gulp. In this article we will have a closer look at Gulp. The post itself is motivated by ASP.NET 6, but does not require, nor make any examples or usage of any ASP.NET 6 feature. Every example is given in form of static files.
Background
In the last 70 years a lot has changed in terms of computing. Programming languages evolved, the hardware improved and everything got connected. One of the most important triggers for improving software development was build automation. The idea is to have several, more or less independent, source files, which have to be build and linked together. The independence is important, because building may take a while and it is therefore beneficial to reduce the build process to only these files, which changed since their last successful build.
The whole description already sounds like an ideal case for automation. We should have a program to do that checking for us, right? Initially a set of scripts had been written to accomplish the goal of a decoupled, integrated build. But the clever people, who have been attracted by the idea of re-usability, took the concept further and created a system called make. It is based on the concept of dependencies. A target (file) has some dependencies. These dependencies may have some dependencies again. In order to resolve a dependency a rule has to be followed. This rule may involve comparison of modification times and more.
Make is quite good and a tool that goes beyond C/C++ or Fortran compilation. It is very useful for web development as well. But it is highly dependent on other scripts or executables. So why not build upon node to start with JavaScript (or the web) right away? The big advantage is the homogeneous architecture. People do not mix languages and the build dependencies are reduced right away. What makes it also appealing is the package manager npm, which represents a separated source to a system-level package manager. So we have a clear separation of concerns.
Now that we are already talking about specialized build systems that require node we need to introduce the Grunt task runner. Grunt was one of the first build automation systems on top of node and is probably the most well-known and established front-end build tool. Why should we consider Grunt over some other tool?
Advantages of Grunt
Grunt describes itself as a task runner. Clearly the concept of a task seems to be eminent. We will basically group our build process into tasks, which can then be linked together (form dependencies) or executed individually. The main idea was to use plugins exclusively. Anything that would be code or in some script form must be covered by a plugin.
Grunt comes also with a nice logo, which is displayed below:

The requirement on plugins does not only omit scripts completely, but also emphasizes the configuration level. Grunt is considered a Configuration-over-scripting build automation system. Its plugins are specialized tools, that have to fit closely in the Grunt eco-system. This sounds like a good idea, but the major principles (similar usage, consistency) are still up to the plugin authors. Nevertheless, the configuration aspect seems to give us a common denominator, which is definitely a good thing to have.
A basic build process using the Grunt task runner is shown in the next image. We can see that each task starts at the disk and ends at the disk. There is no way to keep working on the source in-memory. Therefore intermediate (temporary) directories are mandatory.
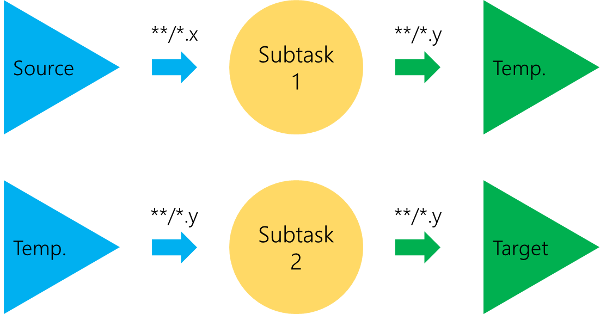
The configuration is usually provided in a simple JavaScript object. This does not have to be a JSON object (JSON objects have a much more strict syntax than plain JavaScript objects). Obviously the configuration will be considered by Grunt. Grunt takes certain sections to identify plugins. These plugins will be called with the provided options.
There are many plugins for Grunt. This is also required. We have already seen that Grunt requires a script to fit in its eco-system. Therefore anything that can be called from Grunt is a Grunt plugin. Without many plugins Grunt would be rather useless. What's also interesting about the Grunt plugin eco-system is the richness of many of these plugins. There are more than just a few plugins that do more than just one thing. On the other hand that is also understandable, since plugins are required and it seems to be easier to write one heavy plugin than multiple lightweight ones. This is also the classic way around the limitations that come with the file based paradigm.
The biggest advantage that can be seen in Grunt is its huge community and vast plugin repository. It is certainly hard to fight against such as established product. Therefore something different is needed, which does not only a few things better, but is in its core different, yet familiar.
More information about Grunt is available on the official homepage at gruntjs.com.
Why Gulp?
Grunt is a hard competitor to play against. Therefore Gulp focuses on a few key points: First and foremost, speed. That speed comes in two flavors. We do not only have superior build system (does usually not matter so much), but also superior development speed (that matters much more). Why is the build speed superior? We will see that Gulp uses streaming, which will keep the working version in-memory, until we decide to create a version on the hard disk with the current contents. Easy CS101 tells us that latency and transfer rates of a computer's main memory is better than the usual HDDs.
The second flavor is more controversial, yet much more important. By allowing any code to run, Gulp manages to get rid of plugins altogether. Of course there are plugins for Gulp (and they are indeed crucial and useful), but they are not mandatory. Therefore Gulp does not require the same amount of plugins that Grunt offers. Also we can often hack in very special things instead of having to search (or write) a plugin. Gulp uses code-over-configuration, which is presumably much better for most developers. Configurations require documentations, coding requires skills. The latter we already have, therefore we should rely on that.
Coming back to Gulp's keypoints. The streaming is centralized by a fluent API, which is much like a shell works. We just pipe the results of one computation to the next. Every computation works with a virtual file system (called Vinyl), which has been written in JavaScript, and should never leave the memory.
Gulp takes its name very seriously, which results in the following logo:

The streaming concept is the core of Gulp. Every other concept is basically derived from it. It is therefore required to spend most of the lines in this article discussing it. As already mentioned we do not produce temporary files. The working copy of the files is stored in the memory. It is also changed there. This is powerful, since it does not only give us a higher modification rate, but also the ability to chain commands together.
What remains is a functional oriented framework with a direct API that reduces the number of temporary files (on disk) to a minimum (usually zero). The following image shows the basic scheme of a build process using Gulp. The changes to the previously shown image of a Grunt are crucial. The subtasks do not output something directly, but rather return a modified stream. This stream can be dumped with another subtask (offered directly by Gulp).
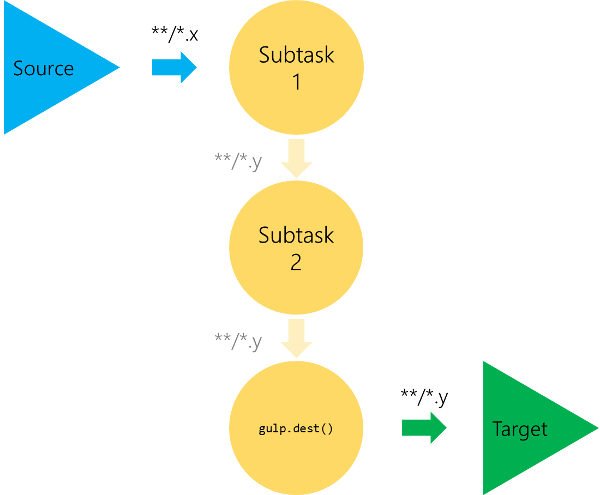
Practically the API is therefore reduced to just a few methods. We need a method for defining a task, which includes potential dependencies and more. We also need a method to convert existing files to virtual ones, i.e. loads the contents of files into memory or transforms files to streams. And finally we also require a method for dumping the current virtual files to the disk, i.e. write out real files. We may also want something like a file system watcher directly in the API, but this is more or less sugar and could be provided by plugins.
Of course the given list is not imaginary, but exists in practice. The following methods are at the center of the Gulp API:
- Define a task with
gulp.task(name, fn) - Convert sources to streams with
gulp.src(glob) - Dump the stream
gulp.dest(folder) - Install a file system watcher
gulp.watch(glob, fn)
The description of a build process that uses Gulp is called a gulpfile. It is pure (and of course valid) JavaScript code. The code is executed via node.js, which means that there is basically no magic going on here by a wrapper. Nevertheless, we do not execute gulpfiles directly via node, but via a custom executable called gulp. This is useful, because it allows us to run whatever task without changing the gulpfile. Within a gulpfile we are free to use whatever node modules (or JS code in general) we want. We are primarily interested in Gulp plugins, which share a simple concept: They are all elementary!
An elementary plugin or code does just one thing, but that one thing really good. It takes arbitrary input, then executes its job and returns some output, such that another elementary plugin could do some work. It is a little streaming based black-box.
This all leads to some direct consequences. Gulpfiles tend to be smaller and easier to read, at least for people with a JavaScript or general programming background. Let's have a look at an example.
First the Grunt configuration:
grunt.initConfig({
less: {
development: {
files: {
"build/tmp/app.css": "assets/app.less"
}
}
},
autoprefixer: {
options: {
browsers: ['last 2 version', 'ie 8', 'ie 9']
},
multiple_files: {
expand: true,
flatten: true,
src: 'build/tmp/app.css',
dest: 'build/'
}
}
});
grunt.loadNpmTasks('grunt-contrib-less');
grunt.loadNpmTasks('grunt-autoprefixer');
grunt.registerTask('css', ['less', 'autoprefixer']);
In contrast the same code can be expressed with Gulp as follows:
var gulp = require('gulp'),
less = require('gulp-less'),
autoprefix = require('gulp-autoprefixer');
gulp.task('css', function() {
gulp.src('assets/app.less')
.pipe(less())
.pipe(autoprefix('last 2 version', 'ie 8', 'ie 9'))
.pipe(gulp.dest('build'));
});
Of course this is just one example and we should not rely too much on line of code comparisons. They are misleading and they will surely tell us the wrong lessons. Comparing the readability would also be a false friend, considering that the example is rather smaller and practical configurations would tend to be much larger. Without further ado let's get started with Gulp to see what's exactly going on here.
Getting started
In the next subsections we will learn everything that is relevant for mastering Gulp. We will install it, create our first gulpfile and study tasks, plugins and important topics such as the glob pattern and watches.
Installation
Before we can use Gulp we should install it. Here we assume that both, node and npm, have already been installed and setup. Now we only need to install Gulp globally, which will enable the gulp command.
We run (with administrative rights, i.e. use sudo or an elevated shell):
npm install -g gulp
The -g flag will tell npm to install Gulp globally. But a global installation is only required for the gulp command. It is not sufficient for using a gulpfile in any project. For using a gulpfile we need a project directory, which means that the directory is the root of an npm package file (package.json). Let's say that we want to create such a file:
npm init npm install --save-dev gulp
Here we initialized an npm based project directory (which will be the current directory, so watch out where you execute the command). We also installed a project-local version of gulp, which has been added to the project's dependencies (--save-dev). The latter is important, since it allows us to omit dependencies from our VCS and re-install all dependencies upon typing npm install later. This is exactly what we usually want.
Now we are good to go! But wait a minute... Why do we need another local version of Gulp? The reason is simple: By having a local version of Gulp for each project, we ensure that each project has exactly the version of Gulp it requires. The package.json does not only list dependency names, but also dependency versions. Of course one is able to allow more modern versions of packages, but in general packages tend to specify versions as exact as possible. This minimizes the risk of facing breaking changes.
Gulp is aware of this method and tries therefore hard to allow specific versions of itself on the same machine. This is achieved by having project-local versions. In the end we lose some disk space, but we win the guarantee that the build system is working when triggered on another machine which did nothing more than cloning the sources and installation the declared dependencies (locally).
Minifying JavaScript files
Let's start with an example. Consider the following directory structure:
. Project Directory |--. bin |--. node_modules |--. src | |--. css | |--. html | |--. js
We have the gulpfile.js in the project directory. Our target is to produce output that may be deployed on the web. Therefore we need some tasks, e.g., to minimize (and combine) certain JavaScript files. We assume that the src directory contains all raw source codes and the bin directory will be the target of our build process.
Let's have a look at a gulpfile that takes a single JavaScript file (called app.js), minimizes it and stores it in the bin folder (no sub-directory, just directly there).
var gulp = require('gulp'),
uglify = require('gulp-uglify');
gulp.task('minify-js', function() {
gulp.src('src/js/app.js')
.pipe(uglify())
.pipe(gulp.dest('bin'));
});
What is happening here? We start by including two modules. The first is Gulp itself. Obviously that is quite important. The second is gulp-uglify, which is basically a JavaScript minification tool. We got a constructor function here, which means that we need to call the uglify function at some point. This is a typical pattern with Gulp plugins, as we will see.
The task method is used to create a new task called "minify-js". This name is arbitrary, but should be a good fit that describes the specified task. The task itself is given in form of a callback. Here we create a new stream that represents the contents of the file located in src/js/app.js, which is then piped to another function created by the uglify constructor. Finally we pipe the modified stream to a function that has been created by calling the dest method with an argument that represents the target directory.
Merging and minifying CSS files
Let's rewrite the previous example to do the same thing for CSS, just not a single CSS file, but a bunch of them. By concatenating them we can combine multiple CSS files in a single one. Thus we will save some requests. Client-side optimization is a wonderful technique for making clients happy and gain more business value. Alright, but the order of CSS files is quite crucial, as certain rules may overwrite previous declarations.
Instead of providing a single string that matches a file, we can therefore also provide a list of strings in form of an array. The order matters. Finally we will now also use another plugin for minification, as the rules for minimizing CSS are quite different to the ones for compressing JavaScript code.
var gulp = require('gulp'),
concat = require('gulp-concat'),
minifyCss = require('gulp-minify-css');
gulp.task('minify-css', function() {
gulp.src(['src/css/bootstrap.css', 'src/css/jquery.ui.css', 'src/css/all.css'])
.pipe(concat('style.css'))
.pipe(minifyCss())
.pipe(gulp.dest('bin'));
});
The underlying principles are the same. We setup our plugins (here we also use the concat plugin to merge files), specify our tasks and call the various constructed functions by piping the stream.
Maybe we even want to store various versions. One that is just the concatenated output (style.css) and one that is the concatenated and minified output (style.min.css). Gulp lets us easily do that, since the output is also just another piped target. Our scheme is therefore changed to something that looks similar to the following picture:
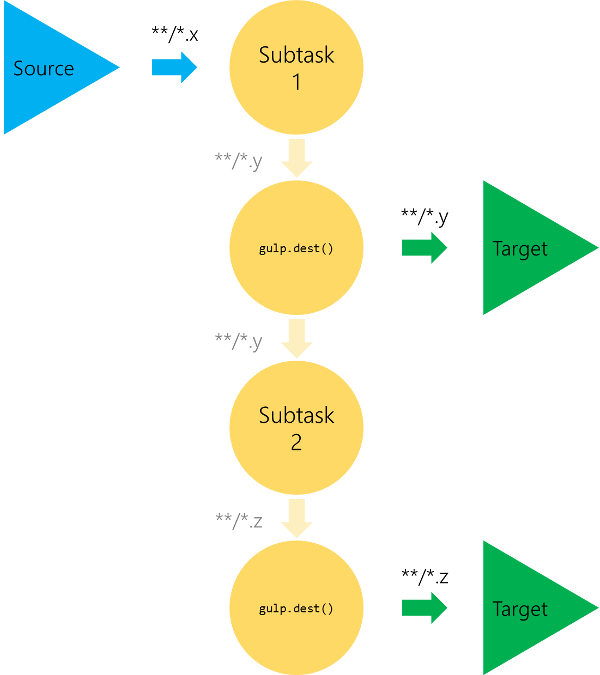
How does that look in code? We will use the gulp-rename plugin for renaming our extension. But the rest should be familiar:
var gulp = require('gulp'),
concat = require('gulp-concat'),
minifyCss = require('gulp-minify-css'),
rename = require('gulp-rename');
gulp.task('minify-css', function() {
gulp.src(['src/css/bootstrap.css', 'src/css/jquery.ui.css', 'src/css/all.css'])
.pipe(concat('style.css'))
.pipe(gulp.dest('bin'))
.pipe(minifyCss())
.pipe(rename({ extname: '.min.css' }))
.pipe(gulp.dest('bin'));
});
Here the whole concept of piping is really useful and allows us to connect the subtasks easily. But this is also a good time to have a closer look at real tasks, which represent combinations of these subtasks (which can be thought of methods that are called with a stream).
Tasks and dependencies
Now that we've seen what we can do it is time to have a closer look at tasks and dependencies. As already noted we need to group everything into tasks. We could have a single task that does everything, but it is definitely not recommended and wouldn't be very agile. Every task is basically a build target. Previously we specified targets such as minifying CSS or minifying JavaScript.
Every target can be called via the gulp command. But every target can also be regarded as a dependency in other targets. Gulp also knows one very special target, which is named default. The default target is the one that is called when the gulp command is invoked without any additional parameter. It is a good practice to consider it a "make all"-kind of instruction. Therefore we would usually provide dependencies on all other (sub-) tasks.
These dependencies are given in form of an array, which contains strings that name the various required tasks (dependencies). Here is a possible definition of the default task:
gulp.task('default', ['clean', 'styles', 'scripts']);
When the default task is built, it requires the clean task to run, then the styles and finally the scripts task. The order is important, even though Gulp can parallelize the build process, if the stream object is not returned. Therefore the clean task must return the stream, otherwise the whole system may be undefined depending on the progress in the sub-tasks.
Let's define the clean task with the required dependencies. Here we provide an additional argument for the src method, which hints that the contents of the directory should not be read. The only thing we care about is the information which directory to clean.
var gulp = require('gulp'),
clean = require('gulp-clean');
gulp.task('clean', function() {
return gulp.src('bin', { read: false })
.pipe(clean());
});
Returning a stream is recommended in any case. Sometimes it may be advantageous to omit it, but most of the time this may lead to undefined behavior. Therefore if we don't care (and know) what should happen, we want to ensure that everything is built in the order we specify.
Running gulp
Now we setup a gulpfile and we are ready to go. What do we have to do for triggering a build? Actually not much. In the simplest case we just run the following command in the project directory. Gulp will then try to find a gulpfile in the current directory.
gulp
This triggers the implicit build process. The implicit version looks for a task called default in the gulpfile and runs it. If the task is not there (or no gulpfile has been found), an error message will be displayed. An error message is also displayed if the script contains any other error.
If we want to be more explicit we can name the task to run. For instance to merge and minify all CSS scripts (second example) we would be forced to run:
gulp minify-css
What if we want to run this and the first example? Either we run two commands, or we enter the gulp command with two arguments, like so:
gulp minify-css minify-js
It is important to emphasize that the local version of Gulp is actually running. The gulp command may be global, but the code that is executing in the end is always local.
Selecting files with globs
We have already seen two possibilities for specifying files: As a single string and as an array of strings. But each string has actually a special meaning and is parsed with a special package. In fact we therefore tend to call these strings globs, since they have to follow certain rules.
In general the term globbing refers to pattern matching based on wildcard characters. The noun "glob" is used to refer to a particular pattern, e.g. "use the glob *.log to match all those log files". Their notation is simpler than, e.g., regular expressions, and without their expressive power. Nevertheless the format contains all features to select and deselect files based on their names.
The allowed glob pattern in Gulp is based on the glob package (available here npmjs.com/package/glob). It is an extension of the usual patterns and has additional regex-like features.
For instance before parsing the path part patterns, braced sections in the strings are expanded into a set. Braced sections start with a { and end with }. A braced section can contain any number of comma-delimited sections within. Braced sections may also contain slash characters, so a{/b/c,bcd} would expand into a/b/c and abcd.
The following characters have special magic meaning when used in a path portion:
- The
*: It matches 0 or more characters in a single path portion (hence no separators, i.e./). - The
?: It matches 1 character in a single path portion. - The
[...]range: Matches a range of characters, similar the range of regular expressions. - The
|: It separated various possibilities in a group (denoted by(...)).
Groups itself must have a prefix that describes their usage. For instance the glob:
!(pattern1|pattern2|pattern3)
matches anything that does not match any of the patterns (pattern1, pattern2, pattern3) provided.
Additionally the following prefixes work with groups:
- The
?: It matches zero or one occurrence of the patterns. - The
+: This is useful if at least one of the patterns has to be matched. - The
*: Is used to match zero or more occurrences of the patterns. - The
@: Matches exactly one of the patterns provided.
Special cases are double stars, given by **. If such combinations are found alone in a path portion, then that matches zero or more directories and subdirectories.
Theory aside what does that mean in practice? If we use "js/app.js" then we match the path exactly. If we would want all other JavaScript files except the formerly given one we could specify "js/!(app.js)". If we want all TypeScript and JavaScript files from a given directory we are free to run "js/*.+(js|ts).
Important plugins
We have already realized that Gulp is powerful and in general independent of particular plugins. However, plugins are very useful and make our life definitely easier. In general we will always prefer a plugin specialized to gulp over some code that has to be integrated with more work.
Plugins are installed via npm just like Gulp itself. They are always locally installed. An example to install the uglify plugin would be:
npm install --save-dev gulp-uglify
These plugins tend to be very small and concise in their usage. Usually everything one needs to know about them is given on their GitHub repository (this is where most of these plugins are hosted) or in the npm system. Otherwise a short look at the source code is manageable.
In this section the most important plugins for general front-end web development tasks will be presented.
General
Here we will look at some of the plugins that are commonly used across a variety of tasks. They could be useful for CSS, JavaScript or other kind of transformations. The following ones seem to be quite useful:
gulp-concat(we've already seen that)gulp-clean(we've already seen that, too)gulp-notify(very useful for notifications)gulp-livereload(will be discussed later in greater detail)
The following example uses the notify plugin to output messages before and after the file merging happens.
var gulp = require('gulp'),
notify = require('gulp-notify'),
concat = require('gulp-concat');
gulp.task('concat', function() {
gulp.src('*.js')
.pipe(notify("Alright, lets merge these files!"))
.pipe(concat('concat.js'))
.pipe(notify("Files successfully merged ..."))
.pipe(gulp.dest('build'));
});
CSS
CSS is one of the primary topics for doing a front-end build process at all. After all CSS preprocessors have been around for quite some time and are probably more useful or used than languages that compile to JavaScript.
Among the many plugins the following ones seem to be worth mentioning:
gulp-sass(convert SASS to CSS)gulp-less(convert LESS to CSS)gulp-minify-css(we've already seen that)gulp-autoprefixer(automatically insert vendor specific prefixes)gulp-imagemin(to compress images)
Autoprefixer is highly useful, but also depends strongly on our needs (most of the time just calling prefixer() without any arguments is sufficient, but some people may need to support even the oldest browsers - hence more options are needed). Therefore we will look at the image minimizer, which can be a true space saver. As already mentioned, front-end performance optimization is never wrong and should always be applied.
var gulp = require('gulp'),
imagemin = require('gulp-imagemin');
gulp.task('images', function() {
return gulp.src('src/images/**/*')
.pipe(imagemin({ optimizationLevel: 3, progressive: true, interlaced: true }))
.pipe(gulp.dest('bin/images'));
});
JavaScript
CSS is quite important, but even more important seems to be JavaScript. Here we care a lot. We do not only want to detect bugs before deployment, but we also want to transform code and maybe even extract documentation. The bug detection is, however, one of the most core features. Not only do we want to run potential unit tests, we also want to do some linting (usually named static code analysis). Lint as a term can also refer more broadly to syntactic discrepancies in general, especially in interpreted languages such as JavaScript.
gulp-jshint(linting for JavaScript)gulp-uglify(we've already seen that)gulp-jscs(checks if a provided style guide is violated)gulp-jsdoc(extracts documentation)
The following example performs some static code analysis on all the JavaScript files in our src folder (and subfolders). The linter must be called twice. Once with the usual creator function, which performs the analysis, and another time with a reporter, that may then evaluate the analysis. The default reporter will output the results. This won't result in any failure if errors occur, which is why there is another reporter - the so called fail reporter. We could use that one with jshint.reporter('fail').
The example only uses the default reporter, but outputs additional (error code) information.
var gulp = require('gulp'),
jshint = require('gulp-jshint');
gulp.task('lint', function() {
return gulp.src('./src/**/*.js')
.pipe(jshint())
.pipe(jshint.reporter('default', { verbose: true }));
});
Caching and more
Until now everything has been build upon request. This may be a giant step back for people that have been used to make's rule system, which always makes a comparison between the last (target) creation and the last (source file) modification time. But in general such a process is neither possible, nor very effective for web development. Of course we don't need to re-compile the whole CSS stuff, if only a JavaScript has been changed. But that's why we have these different tasks. On the other side if we merge and minify JavaScript files, we need to invoke the whole process, even though only a single file changed.
Nevertheless, sometimes we can reduce disk accesses and insert some caches. The following packages can be used to do some filtering and optimize build processes:
gulp-cached()gulp-remember()gulp-changed(filter to only reduce to only changed files)
The following sample makes use gulp-remember and gulp-cached to reduce the amount of minifying work. First we use only changed subset to be uglified, then we add the previously skipped contents. The idea is that the result (the merged file) cannot be cached or remembered, but the single files (source and minified) can be. The cache does therefore two things, build up a cache and use against the cache (i.e. filter out). Remember does also two things, remember the stream result and combine with the previous result.
var gulp = require('gulp'),
cached = require('gulp-cached'),
uglify = require('gulp-uglify'),
remember = require('gulp-remember'),
concat = require('gulp-concat');
gulp.task('script', function(){
return gulp.src('src/js/*.js')
.pipe(cached())
.pipe(uglify())
.pipe(remember())
.pipe(concat('app.js'))
.pipe(gulp.dest('bin/js'));
});
If we would leave out the subtask of merging the files, we could have achieved this with the gulp-changed plugin, which does both. However, that one is more radical and therefore cannot be used in the previous example.
var gulp = require('gulp'),
changed = require('gulp-changed'),
uglify = require('gulp-uglify');
gulp.task('script', function(){
return gulp.src('src/js/*.js')
.pipe(changed('bin/js'))
.pipe(uglify())
.pipe(gulp.dest('bin/js'));
});
Therefore the whole concept of caching is not trivial and very subtle. Most of the times it is better to wait a little bit longer, but have a bug-free build process that does not exclude required files.
LiveReload and BrowserSync
There are multiple plugins that automatically take care about the webbrowsers that are used for viewing the output. In connection with the watches (introduced in greater depth below), they form a great duo. The idea is to start a webserver, which is connected to the webbrowser via a websocket connection. Once the webserver is called with a special command, it sends a message to all connected webbrowsers to refresh. There are more advanced scenarios and usage models, but for an introduction, that knowledge is sufficient.
In the following example the browser-sync plugin is chosen. It does not contain a gulp- prefix and is therefore independent of gulp. The reason for choosing this particular node module is easy: It does not require any browser plugins. It is sufficient to provide a server implementation.
var gulp = require('gulp'),
minify = require('gulp-uglify'),
sync = require('browser-sync');
gulp.task('js', function() {
return gulp.src('src/*.js')
.pipe(minify())
.pipe(gulp.dest('bin'));
});
gulp.task('html', function() {
return gulp.src('src/*.html')
.pipe(gulp.dest('bin'));
});
gulp.task('sync', function() {
sync({ server: { baseDir: 'bin' } });
});
gulp.task('default', ['html', 'js', 'sync'], function() {
gulp.watch(files.js, ['js', sync.reload]);
gulp.watch(files.html, ['html', sync.reload]);
});
In the next section we will also shortly introduce the livereload plugin, which is similar, but more heavyweight.
Watches
File system watches to enable a synchronized / live build process are quite handy. We setup a file system watcher that is triggered once a source file changes. The handler then invokes the build process, which does not only provide immediate build success / failure reports, but also an always up-to-date output directory.
Such a system seems to be in high-demand, which is why the Gulp creators integrated watches out-of-the-box. In Gulp the watches work with a glob object (like a string that follows the described patterns) and dependent tasks. Once any file that matches the glob changes, the dependent tasks will be executed.
A simple example would be the following:
gulp.task('watch-js', function() {
gulp.watch('./src/js/*.js', ['js']);
});
Here we created a task (which has been given the name watch-js), that only binds a file watcher to all *.js files in the src/js folder. Once any of the files changes, the js task will be triggered. But we are not limited to that usage. Much more interesting is the already described case of browser sync. Here we can now trigger a browser reload. Of course this is no simple task, but rather a callback, but Gulp offers a rich event system that can be accessed via the on method. The event is called change. We just bind the changed method of our livereload server instance.
gulp.task('watch', function() {
// Rebuild Tasks
livereload.listen();
gulp.watch(['src/**'])
.on('change', livereload.changed);
});
It is really easy (and quite handy) to bind file system watches and tasks together. This is actually one of the unique selling points of Gulp. But it is also quite simple to write our own plugins.
Writing plugins
Writing our own plugins is also possible. It should not be too surprising that it is actually fairly easy to create such plugins, especially when following the given boilerplate code. We should also follow the pattern to return a creator function, which creates a new through2 object with objectMode enabled. through2 is a tiny wrapper around node streams2 Transform to avoid explicit subclassing noise.
Before we create our own plugin we should read the plugin guide carefully. We can find the guide available at github.com/gulpjs/gulp/blob/master/docs/writing-a-plugin/guidelines.md. Of course we should first have a look if a similar plugin exists, which may be a good basis and is searching for contributions. If not then we need to check if our desired plugin is elementary enough. Otherwise we probably should do it in more plugins (and re-evaluate if any of these smaller plugins is already available).
Finally the guide will also tell us what to do. First we should be independent of Gulp. What's that? That's right! A gulp plugin is independent of Gulp itself. And that makes perfect sense if we think about it. After all Gulp provides only methods that are useful for defining tasks and running them. But a plugin is used in a task and therefore independent of the usual assignments. However, one dependency that should be included is gulp-util. This contains everything from notification connections to error handling. If we throw an exception we should to it via the PluginError class provided in the gulp-util module.
Once we are ready to publish our plugin we also should use the gulpplugin tag. Adding gulpplugin as a keyword in our package.json is beneficial, such that our plugin also shows up on the official search.
So how does the boilerplate code look like?
var through = require('through2'),
gutil = require('gulp-util'),
PluginError = gutil.PluginError;
module.exports = function() {
return through.obj(function(file, enc, cb) {
/* ... */
}));
};
So what are the options in the callback? First we have the virtual file, which is the most important parameter. We should test for empty sets by file.isNull(), in which we directly return. Otherwise we need to distinguish between a buffer, file.isBuffer() and a stream: file.isStream(). We can also test if the given record is a directory via file.isDirectory().
The second option is the provided encoding of the file. This is only interesting for text files, but may be useful in some cases. Finally the callback cb is provided, which is used to return a (possibly modified) stream, e.g. cb(null, file);.
Using the code
The sources that come with this article are a dump of a GitHub repository that contains a lot of Gulp samples. You can find the repository by following github.com/FlorianRappl/GulpSamples. The code is pure, i.e. that dependencies are not included. You will need to run npm install in the directory of a particular sample. Before running any gulp command, you should have also installed Gulp. Other requirements such as node and npm are obvious.
There is a certain chance that one or the other sample is not working depending on when you try to run it. The chance is certainly lower if you get the current version of the samples from GitHub directly. But even then it is possible that breaking changes in Gulp or some plugin occurred. In this scenario the samples would require an update.
Points of Interest
This article is an in-detail version of a talk a gave last year at the WebTechConference in Munich. I think the talk did leave an impression and most listeners considered at least trying out Gulp. I received some really positive feedback regarding the usage of Gulp. For me personally it is clear that Gulp fits an urgent need. If you are satisfied with Grunt or any other build system then stick with it. But if you feel uncomfortable with the one you are using, or you want to try something new, then Gulp is certainly something to look into.
Gulp is fast, very elegant and easy to extend. Did I mention that it is also quite easy? A talk that takes an hour will typically cover everything from basics to writing our own plugins. This is quite an achievement. In a world that is moving fast, technology that makes fun and is easy to learn, yet complex enough to cover all requirements, is hard to find. Gulp manages to succeed in this endeavor by going back to CS fundamentals: provide small building blocks that can be glued together.
Don't forget to check out the GitHub repository. I'll add more samples from time to time and I would be happy to accept pull requests with other samples, if you feel something should be in there (contributions will be mentioned, of course). Also feel free to leave a message if one or the other sample isn't working any more - Gulp is a moving target and I did not restrict the version of Gulp (or any plugin) on purpose. If a sample fails it should be updated. The samples should always work with the latest sources.
History
- v1.0.0 | Initial Release | 15.01.2015