![]()
Introduction
In some projects we might need a proper math parser to either do simple (a little calculator) or more complex mathematics. CodeProject offers us a variaty of math parsers ranging from ports of C/C++ ones to those purely written in C#. This article tries to create a powerful parser in pure C#, using the properties that come with C# and the .NET Framework. The parser itself is perfectly capable of running on other platforms as well, as it has been written on Linux.
The parser itself is Open Source. The full source code of YAMP (that's the name of this parser) is available on Github. A NuGet package will also be available soon.
Personal background
Years ago I've written a math parser using the C# compiler and some
inheritance. The way was to provide a base class that offered all possible methods (like sin(), exp(), ...), which can be used over the inheritance process. Then a string has been built that represented valid C# code with a custom expression in its middle, which has then to be compiled. Of course a pre-parser was necessary to give some data types. On the other side operator overloading and other C# stuff could then be used.
The problem with this solution is that the C# compiler is kind of heavy for a single document of code. Also the resulting assembly had to be loaded first. So after the pre-parsing process we had to deal with the C# compiler and the assembly. This means that reflection was necessary as well. The minimum time for a any expression was therefore O(102) ms. This is far too long and does not provide a smooth handling of input and output.
There are several projects on the CodeProject, which aim to provide a math parser. All of those projects are faster than this previous / old solution - they are also more robust. However, they are not as complete as my project was - therefore I now try to succeed in this very old project with a new way. This time I have built a parser from scratch, which uses (and abuses) reflection and therefore provides an easy to extend code base, that contains everything from operators to expressions over constants and functions. Even assignments and index operators are possible.
What YAMP can do
Before we dig to deep into YAMP we might have a look on what YAMP offers us. First a brief look at some features:
- Assignment operators (=, +=, -=, ...)
- Complex arithmetic using i as imaginary constant.
- Matrix algebra including products, divisions.
- Trigonometric functions (sin, cos, sinh, cosh) and their inverse (arcsin, arccos, arcosh, arsinh).
- More complicated functions like Gamma and others.
- Faculty, transpose and left divide operator.
- Using indices to get and set fields.
- Complex roots and powers.
The core element of YAMP is the ScalarValue class, which is an implementation of the abstract Value class. This class provides everything that is required to do numerics with a complex type. Implementations of the basic trigonometric functions with complex arguments have been included as well.
The MatrixValue class is basically a (two dimensional) list of ScalarValue instances. We might think that it should be possible to make this list n dimensional, however, that would offer some complications like the need to specify a way to set a value in the n dimension. At the moment we will avoid this issue.
Now that we have a brief overview of the main features of YAMP, let's look at some of the expressions that can be parsed by YAMP:
-2+3+5/7-3*2
This is a simple expression, but it already expressions that are not trivial. In order to parse this expression successfully, we need to be careful about operator levels (the multiply operator * has a higher level than the one for subtraction -, same goes for the division operator /). We also have the minus sign used as a unitary operator, i.e. we do not have a heading zero here.
2^2^2^2
This is often parsed wrong. Asking MATLAB for this expression we get 256. That seemed kind of low and wrong. Asking YAMP first resulted in this as well - until we include the rule that even operators of the same level will be treated separately - from right to left. This rule does not make a difference in any expression - except with the power operator. Now we get the same result as Google shows us - 65356.
x=2,3,4;5,6,7
We could use brackets, but in this case we do not need them. This is a simple matrix assignment to the symbol x. Our own assigned symbols are case sensitive, while included functions and constants are not. Therefore we could assign our own pi and still access the original constant by using a different upper- / lowercase notation like Pi.
e^pi
Again, some constants are built in like phi, e and pi. Therefore this expression is parsed successfully. Using YAMP as an external library it is easily possible to add our own constants.
2^x-5
This seems odd, but it will make sense. First of all we have a scalar (2) powered by a matrix (the one we assigned before). This is not defined, therefore YAMP will perform the power operation on every value in the matrix. The resulting matrix will have the same dimensions as the exponent - it will be a 2 times 3 matrix. This matrix then performs the subtraction with 5 (a scalar) on the right side. This is again not defined, therefore YAMP performs the operation on every cell again. In the end we have a 2 times 3 matrix.
y=x[1,:]
We use the range operator : to specify all available indices. The row index is set to 1 (we use rows before columns as MATLAB and Fortran does - and we are now 1 based) - the first row. Therefore the result will be a matrix with dimension 1 times 3 (a transposed three vector). The entries will be 2, 3, 4.
x[:]=8:13
Here we reassign every value of the matrix to a new value - given in the vector 8, 9, 10, 11, 12, 13. If we just use one index it will be a combined one. Therefore a 2 times 3 matrix might have the pair 2,3 as last entry (and the pair 1,1 as first entry), but might also have the index 6 as last entry (and the index 1 as first entry).
xt=x'
The adjungate operator either conjugates scalars (a projection on the real axis, i.e. changing the sign of the imaginary value) or transposes the matrix along with conjugating its entries. Therefore xt now stores a 3 times 2 matrix. If we just want to transpose (without conjugating) we can use the .' operator.
z=sin(pi * (a = eye(4)))
Here we assign the value of eye(4) to the symbol a. Afterwards the value is
multiplied with pi and then evaluated by the sin() function. The outcome is saved in the symbol z. The eye() function generates an n dimensional unit matrix. If we apply trigonometric functions on matrices we end up (as with the power function and others) with a matrix, where each value is the outcome of the former value used as an argument for the specific function.
whatever[10,10]=8+3i
Here two things are happening. First we create a new symbol (called whatever) and then we assign the cell in the 10th row and 10th column to the value 8+3i. So we are able to use indices even on non-existing symbols. We can also expand matrices by assigning higher indices. This is only possible by setting values - we are not available to get higher indices. Here an exception will be thrown.
whatever[2:2:end,1:5]
Here we will get information about all even rows (2:2:end means: start at index 2 and go to the end (a short macro) with a step of 2) with the first half of their columns. The displayed matrix will be a 5 times 5 one with rows 2,4,6,8,10 and columns 1,2,3,4,5.
YAMP does take matrices seriously. Multiplying matrices is done with respect to the proper dimensions. Let's have a look at a sample console application:
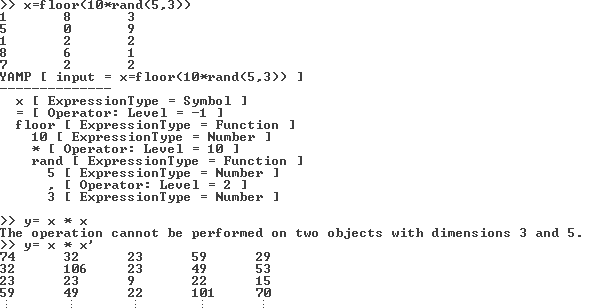
The index operator allows us to select (multiple) columns and / or rows from matrices. The following output shows the selection of the inner 3x3 matrix (from the 5x5 matrix).

This concludes our short look at YAMP. Of course YAMP is also able to perform queries like i^i or (2+3i)^(7-i) or 17! correctly.
How YAMP does it
YAMP contains a few important classes:
ParseTreeValueAbstractExpressionOperatorIFunction
The most important data type for accessing YAMP outside the library is the Parser class. We'll introduce this concept later on.
Right now we want to have a short look at the class diagram for the whole library. First of all the class diagram in principle:
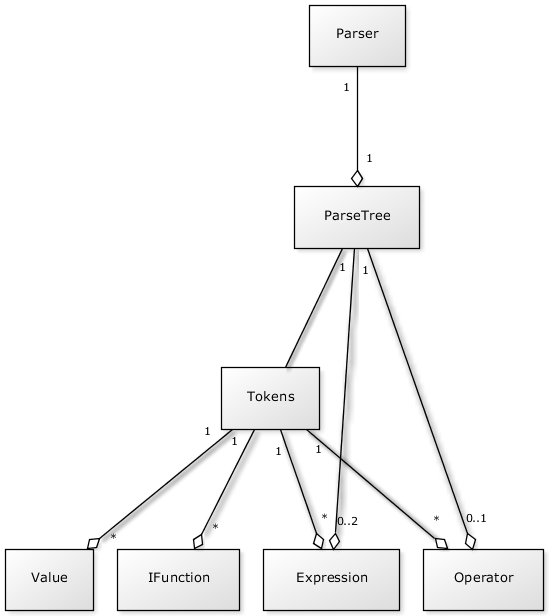
The Parser generates a ParseTree, that has full access to the singleton class Tokens. The singleton is used to find operators, functions, expressions and constants, as well as resolving symbols.
YAMP relies heavily on reflection. The first time YAMP is used might be a little bit slow (compared to further usages). Therefore calling the static Load() method of the Parser should be done before any measurements or user input. This guarantees the shortest possible execution time for the given expression.
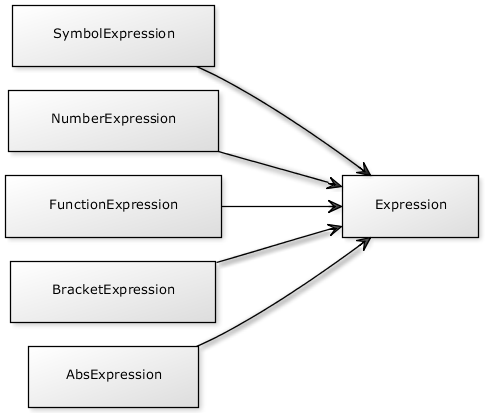
Any expression will always consist of a number of sub-expressions and operators. Operators can either be binary (like +, -, ...) or unary (like !, [], ', ...). The binary ones need two operands (left and right), while unary ones just need one. An expression might be one of the following:
- A bracket expression, which contains a full
ParseTreeagain. - A number - it can either be positive, negative, real or complex.
- An absolute value, which is sometime like a bracket expression that calls the
abs()function after being evaluated. - A symbolic value - either to be resolved (could be a constant or something that has been stored previously) or to be set.
- A function expression can be viewed as a symbolic value that has a bracket expression directly attached (without an operator between the expression).
This results in the following class diagram:
Let's have a look at the class diagram for the operators next:
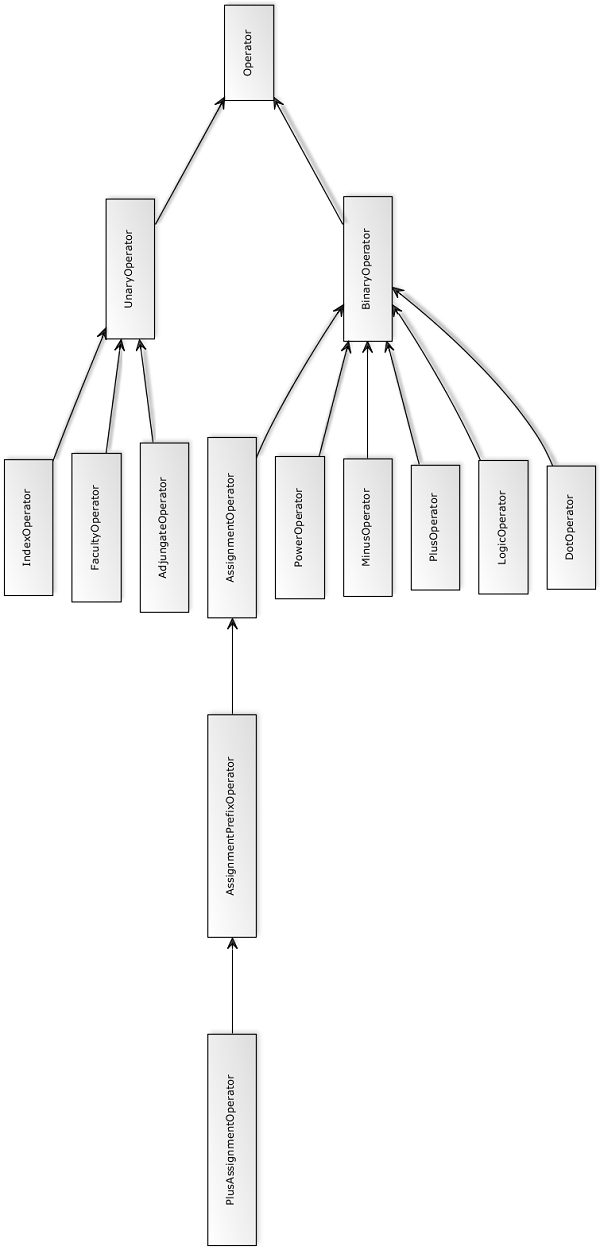
Here we see that the AssignmentOperator is also nothing more than another BinaryOperator. For simplicity and code-reuse another abstract class called AssignmentPrefixOperator has been added as an additional layer between any combined assignment operator (like += or -=) and the original assignment operator. Overall the following assignment operators have been added: +=, -=, *=, /=, \=, ^=.
The difference between the left division (/) and right division (\) is that, while left division means A = B / C = B-1 * C, right
division means A = B \ C = B * C-1. The difference between both can be crucial for matrices, where it matters, if we multiply from left or right. The two operands are always of type Value. This type is an abstract class, which forms the basis for the following derived data types:
ScalarValuefor numbers (can be imaginary)MatrixValuefor matrices (can be only vectors), which consist ofScalarValueentriesStringValuefor stringsArgumentsValuefor a list of arguments
The functions are also a quite important part of YAMP. The class diagram for the functions look like:
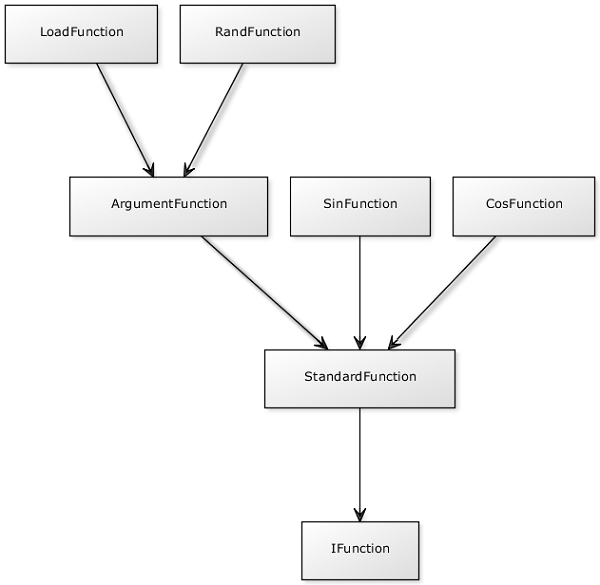
Here we create a standard type StandardFunction. This type has to implement the interface IFunction, as required. The only thing that will be called is the Perform() method. The StandardFunction contains already a framework that works only with numeric types like MatrixValue and ScalarValue. If the Perform() method won't be changed, every number of a given matrix will be changed to the result of the function that is being called.
Another useful type here is the ArgumentFunction type. This one can be used to create a fully operational overload machine. Once we derive from this class we only have to create one or more functions that are called Function() with return type Value. Reflection will find out how many arguments are required for each function and call the right one (or return an error to the user) for the number of given arguments. Let's consider the RandFunction:
class RandFunction : ArgumentFunction
{
static readonly Random ran = new Random();
public Value Function()
{
return new ScalarValue(ran.NextDouble());
}
public Value Function(ScalarValue dim)
{
var k = (int)dim.Value;
if(k <= 1)
return new ScalarValue(ran.NextDouble());
var m = new MatrixValue(k, k);
for(var i = 1; i <= k; i++)
for(var j = 1; j <= k; j++)
m[j, i] = new ScalarValue(ran.NextDouble());
return m;
}
public Value Function(ScalarValue rows, ScalarValue cols)
{
var k = (int)rows.Value;
var l = (int)cols.Value;
var m = new MatrixValue(k, l);
for(var i = 1; i <= l; i++)
for(var j = 1; j <= k; j++)
m[j, i] = new ScalarValue(ran.NextDouble());
return m;
}
}
With this code YAMP will return results for zero, one or two arguments. If the user provides more than two arguments, YAMP will throw an exception with the message that no overload has been found for the number of arguments the user provided.
Implementing new standard functions, i.e., those functions which just have one argument, is easy as well. Here the implementation of the ceil() function is presented:
class CeilFunction : StandardFunction
{
protected override ScalarValue GetValue(ScalarValue value)
{
var re = Math.Ceiling(value.Value);
var im = Math.Ceiling(value.ImaginaryValue);
return new ScalarValue(re, im);
}
}
The implementation of the BinaryOperator class is quite straight forward. Since any binary operator requires two expressions the
implementation of the Evaluate() method throws an exception if the given number of expressions is different from two. Two new methods have been introduced: One that can be
overridden called Handle() and another one that has to be implemented called Perform(). The previous one will be used by the standard implementation of the first one.
abstract class BinaryOperator : Operator
{
public BinaryOperator (string op, int level) : base(op, level)
{
}
public abstract Value Perform(Value left, Value right);
public virtual Value Handle(Expression left, Expression right, Hashtable symbols)
{
var l = left.Interpret(symbols);
var r = right.Interpret(symbols);
return Perform(l, r);
}
public override Value Evaluate (Expression[] expressions, Hashtable symbols)
{
if(expressions.Length != 2)
throw new ArgumentsException(Op, expressions.Length);
return Handle(expressions[0], expressions[1], symbols);
}
}
Let's discuss now how YAMP is actually generated the available objects. Most of the magic is done in the RegisterTokens() method of the Tokens class.
void RegisterTokens()
{
var assembly = Assembly.GetExecutingAssembly();
var types = assembly.GetTypes();
var ir = typeof(IRegisterToken).Name;
var fu = typeof(IFunction).Name;
foreach(var type in types)
{
if (type.IsAbstract)
continue;
if(type.GetInterface(ir) != null)
(type.GetConstructor(Type.EmptyTypes).Invoke(null) as IRegisterToken).RegisterToken();
if(type.GetInterface(fu) != null)
AddFunction(type.Name.Replace("Function", string.Empty), (type.GetConstructor(Type.EmptyTypes).Invoke(null) as IFunction).Perform, false);
}
}
The code goes over all types that are available in the executing assembly (YAMP). If the type is abstract, we avoid it. Otherwise we look if the type implements the IRegisterToken interface. If this is the case we will call the constructor, treat it as a the interface and call the RegisterToken() method. This method usually looks like the following (for operators):
public void RegisterToken ()
{
Tokens.Instance.AddOperator(_op, this);
}
Now we have the case that an operator is searched from our ParseTree. In this case the FindOperator() method of the Tokens class will be called.
public Operator FindOperator(string input)
{
var maxop = string.Empty;
var notfound = true;
foreach(var op in operators.Keys)
{
if(op.Length <= maxop.Length)
continue;
notfound = false;
for(var i = 0; i < op.Length; i++)
if(notfound = (input[i] != op[i]))
break;
if(notfound == false)
maxop = op;
}
if(maxop.Length == 0)
throw new ParseException(input);
return operators[maxop].Create();
}
This method will find the maximum operator for the current input. If no operator was found (the length of the operator with the maximum length is still zero) an exception is thrown. Otherwise the found operator will call the Create() method. This method just returns another instance of the operator.
A simple example of reflection's magic
We've already discussed the ability to add custom functions by deriving either from StandardFunction or ArgumentFunction. If we want to start completely from scratch we could also write an own function class by just implementing the IFunction interface. Let's have now a look at the ArgumentFunction implementation. Here we will see that reflection is quite an important part. First let's look at the code for this class:
abstract class ArgumentFunction : StandardFunction
{
protected Value[] arguments;
IDictionary<int, MethodInfo> functions;
public ArgumentFunction ()
{
functions = new Dictionary<int, MethodInfo>();
var methods = this.GetType().GetMethods();
foreach(var method in methods)
{
if(method.Name.Equals("Function"))
{
var args = method.GetParameters().Length;
functions.Add(args, method);
}
}
}
public override Value Perform (Value argument)
{
if(argument is ArgumentsValue)
arguments = (argument as ArgumentsValue).Values;
else
arguments = new Value[] { argument };
return Execute();
}
Value Execute()
{
if(functions.ContainsKey(arguments.Length))
{
var method = functions[arguments.Length];
try
{
return method.Invoke(this, arguments) as Value;
}
catch (Exception ex)
{
throw ex.InnerException;
}
}
throw new ArgumentsException(name, arguments.Length);
}
}
The crucial part here happens within the constructor. Here the (specific implementation) is inspected. Every method that has the name Function() will be added to a dictionary with the number of arguments as key. The information in the dictionary is then used in the Execute() method. Here the method with the specified number of arguments will be invoked. If the number of arguments does not match any method, an exception will be thrown.
In order to call the Execute() method the method Perform() has been overridden. Here any argument is transformed to an array of Value instances. Usually the number of arguments in the array is one, except if the passed argument is of type ArgumentsValue. In this case the Value type already contains zero to many Value instances.
Parsing a (simple?) expression
In the following paragraphs we are going to figure out how YAMP is parsing a simple expression. The query is given in form of
3 - (2-5 * 3++(2 +- 9)/7)^2.
We actually included some whitespace, as well as some (obvious) mistakes in the expression. First of all "++" should just be expressed as "+". Second the operation "+-" should be replaced by just "-". First of all the problem is divided into two specific tasks:
- Generate the expression tree, i.e. separate operators from expressions and mind the operator levels.
- Interpret the expression tree, i.e. evaluate the expressions by using the operators.
The parser then ends up with an expression tree that looks like the following image.

In the second step we call the method to start the interpretation of the elements. Therefore the interpreter works and calls the Interpret() method on each bracket. Every bracket looks at the number of operators. If no operator is available, then there has to be only one expression. The value of the expression is then returned. Otherwise the Handle() method of the operator is called, passing the array of Expression instances. Since the operator is either a specialized BinaryOperator or a specialized UnaryOperator, the method will always call the right function with the right number of arguments.
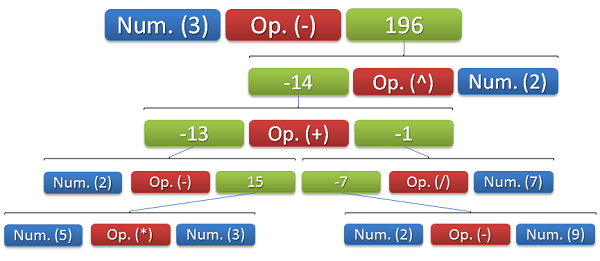
In this example our expression tree consists of five layers. Even though the interpretation starts at the top level (1), it requires the information of the lowest level (5) to be executed. Once 5 has been interpreted, level 4 can be interpreted, then level 3 and so on. The final result of the given expression is -193.
YAMP against other math parsers
We can guess that YAMP is probably slower than most parser written in C/C++. This is just the native advantage (or managed disadvantage) we have to play with. Therefore benchmarks against parser written in C++ may be unfair. Since Marshalling / Interop takes some time as well, parsing small queries and comparing the result might also be unfair (this time probably unfair for the C/C++ parser). Finally a fair test might therefore only consist of C# only parser. Having a look at CodeProject we can find the following parsers:
- MathParser (MP)
- MathParser TK (MPTK)
- MathParser.NET (MP.NET)
- Math Formula Parser (MFP)
- LL Mathematical Parser (LLMP)
We set up the following four tests:
- Parse and interpret 100000 randomly generated queries*
- Parse and interpret 10000 times one pre-defined query (long with brackets)
- Parse and interpret 10000 times one pre-defined query (medium size)
- Parse and interpret 10000 times one pre-defined query (small)
* The expression random generator works like this: First we generate a number of (binary) operators, then we alternate between expression and binary operator, always randomly picking one. The expression is just a randomly picked number (integer) and the operator is a randomly chosen one from the list of operators (+, -, *, /, ^). In the end we have a complete expression with n operators and n+1 numbers.
The problem with this benchmark is that only 3 (YAMP, MathParser.NET, and LL Mathematical Parser) parsers have been able to parse all queries (even excluding the ones using the power operator). Therefore this benchmark was just able to give a speed comparison between these three. However, we can use this test to identify that YAMP is really able to parse a lot of different queries.
If we look at the time that is required per equation in dependency of the number of operators, we see that YAMP scales actually pretty well. MFP and LLMP are significantly better here, however, MFP could not parse much at all and LLMP does not support complex arguments nor does it support matrices.
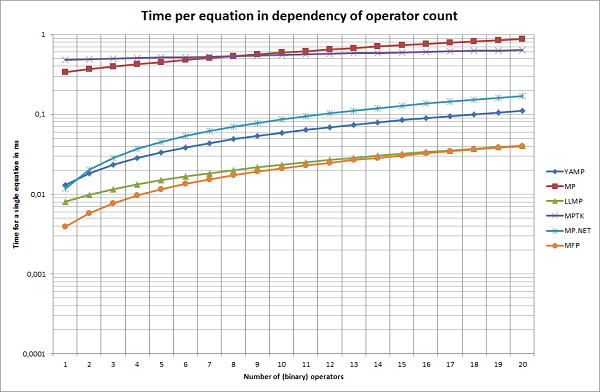
The biggest problem with the fastest implementations are the constraints given by them. They are hard to extend and less flexible than YAMP. While YAMP does contain a lot of useful features (indices, assignments, overloaded functions, ...), none of the other parsers could come even close to the level of detail.
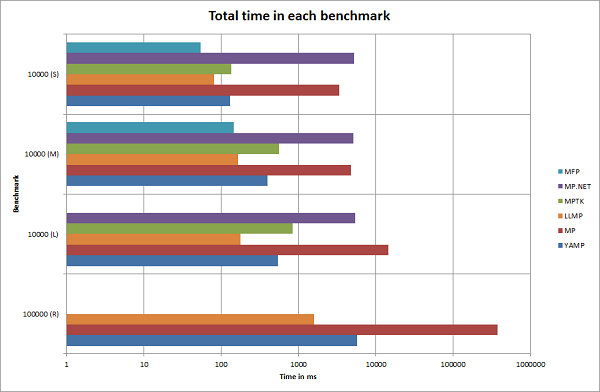
The longer (and more complex) the benchmark, the better for YAMP. This means that YAMP performs solid in the region of short expressions (where no one will notice much about great performance), while it performs great in the region of long expressions (where most would notice delays and other annoying stuff otherwise).
| YAMP | MP | LLMP | MPTK | MP.NET | MFP | |
|---|---|---|---|---|---|---|
| 100000 (R) | 5716 | 372847 | 1611 | x | x | x |
| 10000 (L) | 543 | 14508 | 177 | 850 | 5444 | x |
| 10000 (M) | 398 | 4795 | 167 | 563 | 5122 | 147 |
| 10000 (S) | 131 | 3385 | 81 | 136 | 5194 | 54 |
In the table shown above we see that YAMP can parse all equations and does perform quite well. Considering the early stage of the development process and the set of features, YAMP is certainly a good choice for any problem involving numerical mathematics.
How to use YAMP in your code
If we use YAMP as an external library we need to hook up every chance we want to do. Luckily for us, this is not a hard task. Consider the case of adding a new constant.
YAMP.Parser.AddCustomConstant("R", 2.53);
This way we can override existing constants. If we remove our custom constant later one, any previously
overridden constant will be available again. This way we can also add or remove custom functions. Here our own function needs to have a special kind of signature, providing one argument (of type Value) and returning an instance of type Value. The following example uses a lambda expression to generate a really simple function in one line:
YAMP.Parser.AddCustomFunction("G", v => new YAMP.ScalarValue((v as YAMP.ScalarValue).Value * Math.PI) );
What does it take to actually use YAMP? Let's see some sample first:
try
{
var parser = YAMP.Parser.Parse("2+(2,2;1,2)");
var result = parser.Execute();
}
catch (Exception ex) // this is quite important
{
//ex.Message
}
So everything we need to do is to call the static Parse() method in the Parser class (contained in the YAMP namespace). The method results in a new Parser instance that contains the full ParseTree. If we want to obtain the result of the given expression, we only need to call the Execute() method.
A word of caution here regarding the provided solution: Compiling the console, debug or release project may result in an error, due to a bug in MonoDevelop or Visual Studio. If otherwise referenced projects are excluded from the built mappings (as this is the case with the YAMP.Compare project in these 3 built projects), then an error is thrown on first built. Therefore we have to change the project's mappings to include YAMP.Compare again.
(Current) limitations
YAMP has some limitations. Some of those drawbacks are temporary - others are permanent. Let's have a look what is planned for the future:
- A kind of scripting language with all necessary operators,
if,for,while,switchetc... - Multi line statements
- Custom output formatters (currently the output format is fixed, along with the internal precision and others)
- Ability to set the precision
- Asynchronous calls (you call the parser / interpreter asynchronous, i.e. in a new thread - you have to set an event handler then for getting the result)
- More numeric algorithms
- More logic functions (currently only
isint(),isprime()are implemented) - More options for clearing, loading and saving variables
This is just a short list of planned features. Some of them are easier to implement, some of them are harder. Some of them are in a fixed time window, while others give coding tasks for eternity.
Together with the limitations that will (hopefully) be broken, some limitations, which are here to stay, exist:
- There are no multi-dimensional matrices. A matrix is always 2D at max.
- Matrices can only contain complex numbers (
ScalarValue) and not other matrices, strings etc. - Variables are case-sensitive (along with the case-insensitive constants and functions, this was designed on purpose as a feature).
- Only the previous output is saved in the
$variable - Variables can only contain letters and numbers, while it must start with a letter.
- Overwriting the constant
i(complex identity) with a variable is possible.
YAMP differences between variables and functions, i.e. it is not possible to overwrite a function sin() with a variable named sin.
Points of interest
YAMP makes use of reflection to make extending the code as easy as possible. This way adding an operator can be achieved by just adding a class that inherits from the abstract Operator, BinaryOperator or UnaryOperator class or any other operator that is available.
YAMP is independent of the set culture (the US numbering style has been set as numbering format explicitly). Strings and others are stored with UTF-8 encoding. However, symbols can only start with a letter (A-Za-Z) and can then only contain letters and numbers (A-Za-z0-9).
The project is currently under heavy development, which results in a quite fast update cycle (one to two new versions per week at least). This means that you should definitely consider taking a look at the GitHub page (and maybe this article), if you are interested in the project.
Generally YAMP will require more interested people working on it (mostly on some numeric functions). If you think you can contribute, then feel free to do so! Everyone is more than welcome to contribute to this project.
A strong request If you have something to criticize, then please describe it briefly in a comment. Right now now some people voted 4 without leaving a comment. Usually a vote lower than 5 indicates some wrong behavior or mistake from my side. If this is the case, then please tell me why. Otherwise you should think about why you vote lower than 5, when there is nothing wrong with the article.
History
- v1.0.0 | Initial release | 19.09.2012.
- v1.0.1 | Added a table with benchmark data | 19.09.2012
- v1.1.0 | Added a section with an example process | 20.09.2012
- v1.2.0 | Added a section with limitations | 21.09.2012
- v1.3.0 | Added a section regarding ArgumentFunction | 22.09.2012
- v1.3.1 | Fixed some typos | 24.09.2012