
Contents
Introduction
C# is without any doubt one of the most interesting programming languages. It combines a cleaned syntax of C++ with an efficient virtual machine and a powerful runtime environment. The managed aspects of the language are interesting from a productivity point of view, however, communication with native APIs is indirectly possible. Additionally C# allows the use of pointers within a special context.
This is a kind of article I wanted to write for some time. In this article I will try to bring up things about C# that I find particularly interesting. Most of those tips will be based on very well-known features of C# like attributes or extension methods. The expressiveness of C# is probably unmatched for a strongly typed language with a static type system.
What can one still learn after years of writing applications using C#? Probably not much. But those few things that one has possibly not seen yet might change the way how certain problems are attacked and finally solved. I am aware that some people will know nearly all of those tips, but if there is just one previously unknown tip then this article is already justified.
Background
The most interesting things in C# are actually those things that are powered by the compiler (and not the language). Let's consider two of those examples: async and extension methods. Both are language features. In case of async the compiler uses some .NET-Framework classes (more general ones like Task and additionally more specialized like AsyncTaskMethodBuilder) to construct code, which makes use of the TPL in such a way that we, as a programmer, get a maximum of comfort writing concurrent code. Extension methods are a bit easier, here the compiler just replaces a code structure like a.b() with X.b(a), where X is the static class that exposes the extension method.
A compiler feature is the ability to read out the line number of an instruction, the name of a the calling member and more. Those features are really handy in some situations. The implementation is based on special attributes that are recognized by the compiler. This means that there is a possible interplay between attributes and the compiler. Attributes are therefore much more than just annotations that can be read out by using reflection.
This is the part which makes C# very powerful and brings in a lot of possible compiler enhancements. It is also worth noting at this point that with the new C# compiler, called Roslyn (which is the name of a city in the state of Washington, USA), attributes will be even more powerful. This reasoning behind this is, that previously one could write a kind of C# preparser that will use certain attributes for code-replacements. This could give us some enhancements like e.g. "auto-generated" view models. Previously the idea was that an attribute behind it would behave as an indicator, which still carries semantic even if it is not used in a preprocessor. So there would be no pain if no preprocessor is available. Nevertheless the preprocessor still had some work to do. After this is done the real C# compiler could do his job on the created source. With Roslyn this could be one process.
But it is not the idea of a new C# compiler or a new C# version (v6) that inspired this article, rather than the fact that information regarding quite useful attributes or other features is mostly fragmented. This article tries to bring some of them together - and is of course open for expansion! So if you have a tip that might be interesting for others then feel free to leave a comment or write me a message.
A collection of tips
I gathered a list of tips that is presented in this section. Every tip introduces a particular problem and a common solution. Then the improved solution based on some C# / compiler feature is presented, along with arguments (if not obvious) why this is better.
Generally this article is not about gaining performance with C#, however, in some sections I might be more interested in performance than in others. I will bring up background information on performance issues or possible performance gains if necessary.
Unions
Let's consider that we are writing an application that will do some platform independent graphic process. An example for this would be Oxyplot, which is a plotting library. This library is available for Windows Forms, WPF, Silverlight, ... you name it. If one wants to do something with graphics one has to think about colors. Colors make life more colorful. Of course one knows the Color structure of Windows Forms or the color structure of WPF, however, since we are platform independent we have to introduce our own type.
The color type we want to create should be quite similar to the one from Windows Forms. Therefore we have:
- A field for alpha (byte 0-255).
- A field for red (byte 0-255).
- A field for blue (byte 0-255).
- A field for green (byte 0-255).
This means that our own color structure is 4 bytes long, or the size of an integer. Additionally such a color should be hashable, which is quite convenient, since a hash is also represented by an integer. If we want to compare two colors for equality than we could either use the unique hash or compare each field. If the cost of computing the hash for a color structure is higher than 2 comparisons, we are should always compare the fields to detect equality.
public struct XColor
{
byte red;
byte green;
byte blue;
byte alpha;
public XColor(byte red, byte green, byte blue, byte alpha)
{
this.red = red;
this.green = green;
this.blue = blue;
this.alpha = alpha;
}
public byte Red
{
get { return red; }
}
public byte Green
{
get { return green; }
}
public byte Blue
{
get { return blue; }
}
public byte Alpha
{
get { return alpha; }
}
public int GetHashCode()
{
//Performs automatic computation of the hashcode
return base.GetHashCode();
}
}
Problem: How can we in this scenario boost the performance of our own color type in a hashmap. If we do not override the default behavior for the GetHashCode method, then in case of structure the hash code will be computed from the bit pattern of the instance. We can boost this by pre-caching the hashcode. This has two important consequences:
- The size of the structure will double to 8 bytes since the hashcode has the size of 4 bytes.
- All possible modifications have to trigger a re-computation of the cached hashcode.
This is all quite unhandy and annoying. Finally one might to attack the problem from another side. Color changes are quite rare and therefore one could store the color directly as an integer. This way one already has the cached version of a hashcode (no further computation required), the size is reduced to the original 4 bytes and modifications do not have to trigger a re-computation. However, setting colors like red is more complicated.
Solution: If we think about languages like C/C++ we have the possibility to control the data layout to the bit. In C# the compiler / MSIL will determine the layout. We are only interested what will be in there, not how it is layed out. However, in communication with native APIs a fixed order is quite important, which is why an attribute hsa been introduced to setup layouts of structures.
This attribute StructLayout will notify the C# compiler that layout modifications are enabled and therefore possible by the programmer. The various fields can then be decorated with the FieldOffset attribute. This attribute specifies the position relative to the start of the structure in bytes. An offset of 0 will therefore result in the field being read directly from the beginning of the structure in memory.
Let's use those attributes in our example:
[StructLayout(LayoutKind.Explicit, Pack = 1)]
public struct XColor
{
[FieldOffset(0)]
byte red;
[FieldOffset(1)]
byte green;
[FieldOffset(2)]
byte blue;
[FieldOffset(3)]
byte alpha;
[FieldOffset(0)]
int value;
public XColor(byte red, byte green, byte blue, byte alpha)
{
//The following line is important in this case
this.value = 0;
this.red = red;
this.green = green;
this.blue = blue;
this.alpha = alpha;
}
/* The rest */
public int GetHashCode()
{
//Just returns the value - the best and fastest hashcode
return value;
}
}
Please note the change in the constructor. We need to tell the compiler explicitly that we are actually setting all fields, even though the value field is just a combined representation of all the other fields. Thanks to Paulo for pointing that out!
This is the most performant way possible. The structure is only 4 bytes long, however, sub-sections of it are treated differently. If we talk to the value field, we will talk to the entire structure. If we access the green field we only use the subset of the 2nd byte. There are no bit-operators or whatsoever required here, everything just uses different representations on the same data internally, which is ultra fast.
Where is this technique useful? There are multiple applications, e.g. to have a very fast reduced index translation (2D to 1D and vice versa). In the past I used this pattern mostly to gain performance or reduce size overhead.
Where does this pattern not work? Well, unfortunately it does not work with managed objects, i.e. any instance of a .NET class or delegate. First of all we can only declare those layout options on structures. Second we can also only use fields that are structures again. CLR classes will have the problem of actually being more heavy than they look, since they have a small prependix, which stores the pointer to the type information. This enables features like is, the powerful dynamic casting enhanced with RTTI (runtime-type information) and more, but acts as a disadvantage in this case.
→ Example code unions.linq
Sealing
Sealing is useful if one wants to stop the chain of inheritance. Most people know that it is possible to use the sealed keyword on classes. This is a quite obvious use-case, since classes are the only abstract objects taking part in inheritance. Interfaces can always be implemented, structures, enums and others can never be inherited.
However, the sealed keyword can also be applied to methods. This does not have such a strong affect as sealing a whole class, but could be useful at some point. Before we can discuss if this is really necessary and what the advantages we get, we have to discuss sealing in general.
In general there are three kinds of C# programmers:
- People that do not know (or care) about sealing at all
- People that are strongly against sealing
- People that are strongly in favor of sealing
In general I would consider myself being in the third group. However, it is worth noting here that putting sealed on a class could do more harm than be benficial, so being defensive here might be better than blindly sealing everything. Personally I use the keyword for classes that are not supposed to be inherited at all, and if so then just on a library level (such that if I need to change this later on, only the internal library is affected).
Therefore it is legal to say that sealing is a way of giving other programmers directions on how to use (or extend) our system.
However, while the first group of people should not be discussed any further, it is definitely interesting to have a close look at the arguments of the second group. Basically these arguments can be summed up to the following statements:
- The performance benefit (if any) is neglectable
- It breaks the idea of extending existing types
- OOP is based on polymorphism and inheritance is an important aspect of this
We will discuss the possible impact on performance later on. Right now the latter two arguments should be examined more closely. Those two arguments are based on the assumption that inheritance is key and always makes sense. However, this is certainly not true. JavaScript for instance is an OOP language, without any classes. In JavaScript objects create objects using the prototype pattern and any existing object can be the "parent" object of another object, which acts more or less like the instance of a base class.
As far as the extension of an existing class goes, sealing is not the core of the problem. In my opinion one should always just depend on interfaces, which are to me something like compiler contracts. An interface is telling the compiler "I don't know the exact type, but I know that kind of functionality will be in there". A perfect interface would add zero overhead, since it is just about the definition from the perspective of a compiler. In this scenario TypeScript does a wonderful job, where every definition is based on an interface, which is completely transparent at run-time (since only the compiler used it for checking the source - the interface definition is completely gone in the compiler JavaScript code).
Therefore I strongly suggest to consider using interfaces for every dependence. If one is really dependent on a specific kind of object, then one can always think about if sealing the underlying class of this object is a good idea.
Coming back to the performance argument. The usual statement is that the performance can benefit from sealing a class. Similarly the performance might benefit from sealing single methods, if sealing the whole class is too much. Essentially, this benefit has to do with the fact that the runtime does not need to worry about extensions to a virtual function table. A sealed class can't be extended, and therefore, cannot act more polymorphic than its base class. In the real-world I have not seen a single case, where sealing a full class (or a bunch of methods of a class) resulted in a detectable performance gain.
All in all I think we should never seal a class just due to performance reasons. The right argument for sealing should be to give other programmers some hint what should be used as basis for extensions and what should not (because it cannot). In general we should use sealed on classes marked as internal by default, and avoid using sealed as default for public ones.
Let's take a look at a short sample:
class GrandFather
{
public virtual void Foo()
{
"Howdy!".Dump();
}
}
class Father : GrandFather
{
public sealed override void Foo()
{
"Hi!".Dump();
}
}
sealed class Son : Father
{
}
The question now is: Can we expect compilation to use call instead of callvirt? The answer is obviously no...
IL_0000: newobj UserQuery+GrandFather..ctor
IL_0005: callvirt UserQuery+GrandFather.Foo
IL_000A: newobj UserQuery+Father..ctor
IL_000F: callvirt UserQuery+GrandFather.Foo
IL_0014: newobj UserQuery+Son..ctor
IL_0019: callvirt UserQuery+GrandFather.Foo
This has been compiled with optimizations. Even though it should be quite clear in the case of Son that the base class Father has the final version of the Foo() method, a callvirt instruction is used.
→ Example code sealing.linq
Readonly and const
Of course every C# programmer knows the two keywords readonly and const. Both can be used for non-changing values. If we use the combination static readonly, we can have a variable that behaves quite similar to a const declared field. However, let's note some important aspects of constant expressions:
constrequires a primitive type (int,double, ... andstringinstances)constcan be used as cases in a switch-case statementconstexpressions will lead to compile-time replacements and evaluations
On the other hand, any static field acts only as a normal field, with the property of being independent of a specific class instance. This means that a static readonly field is just a normal instance-independent field, with the property of initially being set by the constructor and no possibility of changing it later on.
Let's see a short sample code with some constants used in a standard expression.
const int A = 3;
const int B = 4;
void Main()
{
int result = A + B;
result.Dump();
}
How many add operations does our program perform? The answer is zero! Why? Well, since both, A and B are compile-time constants, the optimizer can perform a trivial optimization in form of replacing the binary add operation with a constant, which represents the result of the operation.
IL_0000: ldc.i4.7
IL_0001: stloc.0 // result
IL_0002: ldloc.0 // result
IL_0003: call LINQPad.Extensions.Dump
Now we change the code slightly by using static readonly.
static readonly int C = 3;
static readonly int D = 4;
void Main()
{
int result = C + D;
result.Dump();
}
What's the number of add operations this time? Of course its one! Why? The compiler does not perform a replacement of the two variables, C and D. Therefore there are actually no constants in the expression and thus the binary operation has to be evaluated at runtime.
IL_0000: ldsfld UserQuery.C
IL_0005: ldsfld UserQuery.D
IL_000A: add
IL_000B: stloc.0 // result
IL_000C: ldloc.0 // result
IL_000D: call LINQPad.Extensions.Dump
We already see when we should use constants and when we should prefer static readonly fields. If the use-case is unknown then the latter should always be preferred. If we require the field in switch-case statements (and of course if the value is of a primitive type), then const is needed. Otherwise const should only be used for constants that really stick to that name: Fields that will never change in the future.
A great example is Math.PI. On the other side connection strings and such should never be stored as a constant. The reason is quite simple: Let's consider we have a library that uses the constant field with our connection string. If we change this main assembly, we also have to recompile all other assemblies that are based on this one, since constants are inserted at compile-time. This would not be the case with a static readonly variable due to the access of the field being postponed until runtime.
→ Example code constread.linq
Friend classes
C++ introduces the concept of friend classes. A friend class is a another class, which has access to the private members of the current class. This concept is like saying "I am a class and my private fields are secrets, however, I can share these secrets with my friends".
Obviously from an architect's point of view friend classes are the solution to a problem that should not exist. A class should actively perform information hiding. We are not interested in the implementation, but rather in the functionality that can be obtained by using a class. If another class does not only require a specific class as input, but also a specific implementation within the specific class, we do not only have a strongly coupling, but a quite unhealthy relationship that is neither robust, nor very flexible.
Nevertheless sometimes there is a strong relationship between two classes. The .NET-Framework does also contain such classes. An example? The generic List<T> class uses a special implementation of the IEnumerable<T> interface as basis for an iterator. The reason for not using a more general one is that this allows a specialized implementation, which takes advantage of the internal implementation of the list type itself.
How is it possible for some class to access the internal implementation of another class, without being a derivative? The answer to this question is a nested class. In case of the list, it is a nested structure, which follows the same principle.
Let's have a look at some sample code:
interface SomeGuy
{
int HowOldIsYourFriend();
}
interface OtherGuy
{
}
class MyGuy : OtherGuy
{
private int age;
public MyGuy()
{
age = new Random().Next(16, 32);
}
class MyFriend : SomeGuy
{
MyGuy guy;
public MyFriend(MyGuy guy)
{
this.guy = guy;
}
public int HowOldIsYourFriend()
{
return guy.age;
}
}
public SomeGuy CreateFriend()
{
return new MyFriend(this);
}
}
In the example we want to establish a friend relationsship from MyGuy to SomeGuy. Of course it could be possible to return the class MyGuy.MyFriend, but then we would need to change the access modifier on the nested class as well as showing a piece of the internal information. In this case we want to hide that the class we are creating as a friend is actually nested.
This this example require the given constructor? Not really. Since a nested class is within the scope of a parent class, it will always have access to private members of an instance of the parent class.
Let's modify our sample:
interface SomeDude
{
void WhatsHisAge(OtherDude dude);
}
interface OtherDude
{
}
class MyDude : OtherDude
{
private int age;
public MyDude()
{
age = r.Next(16, 32);
}
class MyFriend : SomeDude
{
public void WhatsHisAge(OtherDude dude)
{
var friend = dude as MyDude;
if (friend != null)
("My friend is " + friend.age + " years old.").Dump();
else
"I don't know this dude!".Dump();
}
}
public SomeDude CreateFriend()
{
return new MyFriend();
}
}
Of course we would not require the cast in case of MyDude being passed. Nevertheless this way we are only coupled to interfaces and we could write friend classes, but we don't have to.
We already discussed that some .NET internal classes are using this trick to gain some performance by relying on the internal implementation of another class. What I think is particularly interesting is the fact that you could combine this nested class approach with a class marked as partial. This way you could write a proxy, where every proxy would sit in its own file. Each file would consist of two parts. One would be the proxy implementation, with the other one being the partial class with the nested class sitting inside. This way one could really mimic friend classes in a more or less transparent way.
However, talking of a proxy we might discover something else. The .NET-Framework already has a pre-made solution for a proxy that will handle an arbitrary class, as long as it implements MarshalByRefObject. This is pretty nifty and might have some really cool applications. For instance one could automatically wrap all performance-relevant classes in such proxies, which will give us automated invocation measurements.
The .NET RealProxy class lets us create a transparent proxy to another type. Transparent means that it looks completely like the target object, which is proxied, to other objects. However, in fact its not: it's an instance of your class, which is derived from the RealProxy. The is the main downside of RealProxy is that the type to proxy must either be an interface. Also, as already said, a class that inherits from MarshalByRefObject will also do the job.
This lets us for instance apply some interception or mediation between the client and any methods invoked on the real target. We could then couple this with some other techniques like the factory pattern. This way we could hand back transparent proxies instead of real objects. This allows us to intercept all calls to the real objects and perform other code before and after each method invocation.
Let's just use the class that is located in the System.Runtime.Remoting.Proxies namespace. In the next sample we create a proxy that is based on an existing object. However, one could also use the proxies for mocking objects using interfaces. This time we are, however, interested in just wrapping the call an existing object.
class MyProxy<T> : RealProxy
{
T target;
public MyProxy(T target)
:base(typeof(T))
{
this.target = target;
}
public override IMessage Invoke(IMessage msg)
{
var message = msg as IMethodCallMessage;
var methodName = (String)msg.Properties["__MethodName"];
var parameterTypes = (Type[])msg.Properties["__MethodSignature"];
var method = typeof(T).GetMethod(methodName, parameterTypes);
var parameters = (Object[])msg.Properties["__Args"];
var sw = Stopwatch.StartNew();
var response = method.Invoke(target, parameters);
sw.Stop();
("The invocation of " + methodName + " took " + sw.ElapsedMilliseconds + "ms.").Dump();
return new ReturnMessage(response, null, 0, null, message);
}
}
We have to override the Invoke method. This method gives us an IMessage instance (from the class in the System.Runtime.Remoting.Messaging namespace), which contains all information about the call. This way we can read out everything that is required for invocation of another method. In this case we are starting and stopping a new stopwatch. Afterwards we return the result of the call and dump the result of the stopwatch evaluation.
Creating and using this proxy is quite simple. We could write the following helper method:
T CreateProxy<T>(T target) where T : class
{
var proxy = new MyProxy<T>(target).GetTransparentProxy();
return proxy as T;
}
Finally we might use it as follows. Let's assume we have a class called MyClass. Let's see how this looks like:
class MyClass : MarshalByRefObject
{
public void LongRunningProc()
{
Thread.Sleep(1000);
}
public string ShortRunningFunc()
{
Thread.Sleep(10);
return "test";
}
}
How can we wrap this and talk to the code? This is straight forward with our helper method:
var real = new MyClass();
var proxy = CreateProxy(real);
proxy.LongRunningProc();
proxy.ShortRunningFunc().Dump();
Proxies might come in handy in scenarios where direct invocation is unwanted. If this scenario is quite special (limited to one class, with a limited set of methods) then using the RealProxy might be too much. Otherwise using this class is very useful and might come in just right.
→ Example code friend.linq
Debugger attributes
We might be interested in a list of useful attributes for controlling the debugger or the compiler in general.
Let's have a short look at a list of very useful attributes:
//Ensures that the method is not inlined
[MethodImpl]
//Ensures that execution is only possible with the given symbol being defined
[Conditional("DEBUG")]
//Marks a method or class as being deprecated
[Obsolete]
//Marks a parameter as being the name of the file where the caller of the method is implemented
[CallerFilePath]
//Marks a parameter as being the integer line number in the source where the current method is called
[CallerLineNumber]
//Marks a parameter as being the name of the method that contains the call to the current method
[CallerMemberName]
//Sets the display of the class in the debugger
[DebuggerDisplay("FirstName={FirstName}, LastName={LastName}")]
//Instruments the debugger to skip stepping into the given method
[DebuggerStepThrough]
//Similar to stepthrough, hides the implementation completely from the debugger
[DebuggerHidden]
//Handy for unit testing: Lets internal types be visible for another library
[InternalsVisibleTo]
//Sets a static variable to be not shared between various threads
[ThreadStatic]
What's the difference between the DebuggerHiddenAttribute and the DebuggerStepThroughAttribute class? While both can be set on methods, the [DebuggerHidden] annotation cannot be set on classes. The next, and probably crucial difference, is that code that is annotated with the [DebuggerStepThrough] attribute will be shown in the call stack as external code. This will give us at least some indication that some other code is running.
On the other side with the [DebuggerHidden] flag we will not see any indication of code running at all. From the call stack's point of view it is, as if the hidden code does not exist!
So let's see some examples. Let's start with the very useful parameter naming first. We could write a method like the following:
void PrintInfo([CallerFilePath] string path = null, [CallerLineNumber] int num = 0, [CallerMemberName] string name = null)
{
path.Dump();
num.Dump();
name.Dump();
}
Calling this method directly and without giving any parameter a value, will result in these values being inserted by the compiler. It will automatically insert the right values, like the current line number or the name of the method that calls the PrintInfo method in this case.
Finally we might only want to print the caller information in debug mode. We can do it by annotating the method:
[Conditional("DEBUG")]
void PrintInfo([CallerFilePath] string path = null, [CallerLineNumber] int num = 0, [CallerMemberName] string name = null)
{
path.Dump();
num.Dump();
name.Dump();
}
Of course the DEBUG symbol is very handy, since it will be activated in debug mode as the default setting in the Visual Studio IDE. However, sometimes we might want to introduce our own symbols. Let's consider the following:
#define MYDEBUG
/* ... */
[Conditional("MYDEBUG")]
void PrintInfo([CallerFilePath] string path = null, [CallerLineNumber] int num = 0, [CallerMemberName] string name = null)
{
path.Dump();
num.Dump();
name.Dump();
}
If we comment the first line then the PrintInfo() will not be called. Otherwise all calls will be taken into account and executed during runtime.
→ Example code debugger.linq
Aliasing
The using keyword is a really great feature of the C# language. The great part is that one does not have to write using namespace as in C++, but only using. Additionally one can use (!) it for automatically releasing disposable objects, i.e. calling the Dispose() method of objects implementing IDisposable automatically.
The following method creates a new file called foo.txt.
using (File.Create(@"foo.txt")) ;
The whole using block does quite some work for us.
IL_0005: ldstr "foo.txt"
IL_000A: call System.IO.File.Create
IL_000F: stloc.1 // CS$3$0000
IL_0010: leave.s IL_001C
IL_0012: ldloc.1 // CS$3$0000
IL_0013: brfalse.s IL_001B
IL_0015: ldloc.1 // CS$3$0000
IL_0016: callvirt System.IDisposable.Dispose
IL_001B: endfinally
So we get a try-finally block for free, which will always use the Dispose() method in the finally clause. Therefore we can be sure that the finalizer of the resource we are using is actually called.
Let's go back to the original meaning of a using directive. Let's consider the following code:
using System.Drawing;
using System.Windows;
Problem: If we want to create instaces of a type like Point, we need to specify the full namespace path. This is because the name Point is ambiguous between System.Drawing.Point and System.Windows.Point. While this full specification is a possible solution, it might not be the ideal solution.
Solution: Let's consider that our code requires System.Windows.Point only at one point to set some value by converting a System.Drawing.Point. Why should we use the full namespace? Additionally we might have other name collisions, that could also be avoided by just omitting the second using statement.
The perfect solution will still shorten the qualifier for the Point type located in System.Windows. Something like the following would do the job:
using System.Drawing;
using win = System.Windows;
Every time we referred to some type in System.Windows namespace we have to add the win. prefix. However, if our problem is just the single ambiguity that has been created by using the other Point, we might have also chosen the following statements:
using System.Drawing;
using WinPoint = System.Windows.Point;
This is what we can call an alias for a type, or short a type-alias. This is actually very similar to a typedef declaration in C/C++. If we play around with this we will notice the following interesting behavior:
using System.Drawing;
using var = System.Windows.Point;
This is actually possible! Of course it is a very evil anti-pattern, and lucky as I am I never saw it in real-world code. But why is this possible? Obviously var is not a normal keyword. In fact, var is already an alias, however, a kind of dynamic alias. The compiler re-defines the meaning of var permanently, to match the exact type of the right hand side of an assignment. We can override this behavior by specifying a non-dynamic (fixed) value for var.
This aliasing can be very useful for generics. Let's consider the following code:
List<KeyValuePair<string, string>> mapping = new List<KeyValuePair<string, string>>();
mapping.Add(new KeyValuePair<string, string>("default", @"foo.txt"));
This is quite long and looks ugly. If this only occurs in one file an alias seems to come in very handy! So let's use an alias called StringPair for the KeyValuePair<string, string>.
using StringPair = System.Collections.Generic.KeyValuePair<string, string>
// ...
List<StringPair> mapping = new List<StringPair>();
mapping.Add(new StringPair("default", @"foo.txt"));
Aliases should always be used with some caution. They might be confusing and could make the problem more complex. However, in some situations they might be just the right solution for making the code more elegant and easier to read.
→ Example code aliasing.linq
Operational interfaces and enumerations
Interfaces are among the top features of C# (or Java). In fact I always recommend doing interface definitions for core-abilities. We can also follow the rule of thumb that if one is unsure whether to take an abstract base class or an interface as an implementation basis, an interface is the right choice. Also for dependencies an such, an interface will be the right choice if there is any uncertainty.
In general interfaces allow a much greater flexibility in our code. They simplify testing and they can be combined nicely. Additionally since C# has extension methods, we can actually give them some implementation, from a code-reader's point of view. This is actually what will be discussed in this section. Here it is worth noting that it is just the reader's POV, not the program's POV. For the program the interface still does not have that one method. Instead it is a static class that offers a function, which just takes an instance of a class, that implements this interface, as its first argument.
To see that this is really handy, let's consider the following class diagram, which shows the outline for the specification pattern:
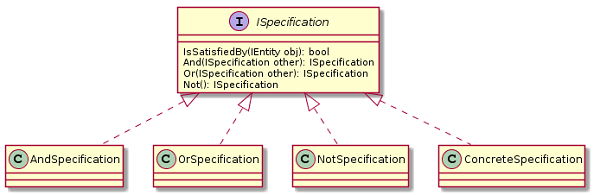
Of course we might be interested in always implementing the same methods And, Or and Not. But even if we outsource these three methods to a static class, and replace them by something like the following, we would still need to do copy and pasting all the time:
public ISpecification And(ISpecification right)
{
return SpecificationImplementation.And(this, right);
}
public ISpecification Or(ISpecification right)
{
return SpecificationImplementation.Or(this, right);
}
public ISpecification Not()
{
return SpecificationImplementation.Not(this);
}
This is quite boring and error-prone as every copy-paste process (even though this is really simple and probably everything in this robotic work might be done without any mistake). So we could do some really simple modification on the described pattern.
Basically we will just exclude these three methods from the interface. Then we re-include them by implementing three extension methods. In the end we have some code that reads as follows:
static class Extensions
{
public static ISpecification And(this ISpecification left, ISpecification right)
{
return new AndSpecification(left, right);
}
public static ISpecification Or(this ISpecification left, ISpecification right)
{
return new OrSpecification(left, right);
}
public static ISpecification Not(this ISpecification value)
{
return new NotSpecification(value);
}
}
The great thing with extension methods is, that they are always exchangeable by re-implementing the same extension methods in a different namespace and using the other namespace. Additionally real methods are always preferred to extension methods, which allows a specific class to add methods with the same name as the extension method. It should be noted that this will not result in polymorphic behavior, since the compiler has to select the right method.
This means that there is certainly no vtable and no call virt being executed here. On the other side we can use this technique to give objects like instances of delegate or enum types some additional behavior. Let's start with a simple enumeration.
enum Duration
{
Day,
Week,
Month,
Year
}
Now we can apply an extension method to bring in some really handy stuff. In this case we might just enhance the enumeration type with the possibility to use together with a DateTime value. This makes enumerations even more useful than before and makes them look like class instances with functionality.
static class Extensions
{
public static DateTime From(this Duration duration, DateTime dateTime)
{
switch (duration)
{
case Duration.Day:
return dateTime.AddDays(1);
case Duration.Week:
return dateTime.AddDays(7);
case Duration.Month:
return dateTime.AddMonths(1);
case Duration.Year:
return dateTime.AddYears(1);
default:
throw new ArgumentOutOfRangeException("duration");
}
}
}
The same trick can be applied to any delegate. Let's just have a short look at a small sample illustrating this.
static class Extensions
{
public static Predicate<T> Inverse<T>(this Predicate<T> f)
{
return x => !f(x);
}
}
/* ... */
Predicate<int> isZero = x => x == 0;
Predicate<int> isNonZero = isZero.Inverse();
While this is quite interesting, there are not many applications that would actively benefit from such a coding style. Nevertheless its good to know that C# gives us possibilities of using those delegates like first class object oriented elements.
→ Example code operational.linq
Undocumented features
C# has some undocumented features that could be used in very special scenarios. All special constructs start with a double underscore and are not covered by intelli-sense. Among some of the possibilities with those undocumented features, I want to discuss the following two aspects:
- References
- Arguments
References can be generated by using the __makeref construct. This function takes a single object as input and returns an instance of type TypedReference. This instance can then be used for further examination with the __reftype function. Here we get back the underlying Type of the original object. Finally there is also the option to return the value of the stored reference. This is possible by using the __refvalue function.
The TypedReference type represents data by containing both a reference to its location in memory as well as a runtime representation of the type of the data. Only local variables and parameters can be used to create an instance of the TypedReference type. This excludes fields from being used to generate such instances.
Let's have a look at the previously introduced functions in action:
int value = 21;
TypedReference tr = __makeref(value);
Type type = __reftype(tr);
int tmp = __refvalue(tr, int);
type.Dump();
tmp.Dump();
The second aspect that we will have a look it is an variadic list of arguments. In C# we would usually use a params keyword to auto-generated an array of inputs. However, there is a second possibility using the undocumented __arglist function. This function takes an unknown number of parameters and wraps them in a special kind of variable. The target function can then take an instance of type __arglist to generate some additional code. This code can then be used to instantiate a new ArgIterator.
Let's see how this could be used:
void Show(__arglist)
{
var ai = new ArgIterator(__arglist);
while(ai.GetRemainingCount() >0)
{
TypedReference tr = ai.GetNextArg();
TypedReference.ToObject(tr).Dump();
}
}
So we are back to our TypedReference type. This is quite interesting, since this just means that the variadic arguments list uses references to transparently go from one method to another. The method GetNextArg is used to dequeue the head of the remaining list of arguments. By using the GetRemainingCount we can access how many remaining arguments are stored in the list of arguments.
LINQpad is able to compile all queries with the undocumented feature. However, LINQpad will show some errors in the editor. This is maybe confusing, but not really a problem.

Right now I would say that the undocumented features should not be touched unless one uses them to solve a very special problem. And in this case one should think about placing some abstraction for the used undocumented features, such that transforming the code from using the undocumented features to not using them can be done by just changing the implementation of the abstraction.
This is required, since there is no guarantee that those features will be available at some point in the future.
→ Example code undocumented.linq
Indexers
Indexers are really useful and quite interesting. They are created as follows:
class MyClass
{
public int this[int index]
{
get { return index; }
}
}
Of course we are not restricted to a single indexer. Additionally we can use other types like a string. Therefore the following is possible as well:
class MyClass
{
public int this[int index]
{
get { return index; }
}
public string this[string key]
{
get { return key; }
}
}
Now we could try to go one step further and look if it is also possible to define indexers with generic parameters like a generic method. However, we would just realize that unfortunately this is not possible. Additionally keywords like ref or out are also not possible. Nevertheless such an indexer is therefore quite similar to a method. In fact, like properties, indexers are just methods that will be generated by the compiler.
Since indexers are just methods, we can use them with the params keyword.
class MyClass
{
public int this[params int[] indices]
{
get { return indices.Sum(); }
}
}
This is all quite nice and could be very useful in some situations. However, there is one drawback that comes with the fact, that indexers are just methods. The compiler needs to select a proper for the indexer. And the default name is just Item. Since indexers are like properties, we have a possible get and a possible set method. Therefore the get method would be named get_Item and the set method would be named set_Item.
Now its unlikely that we will name a method like this. First of all we should not use lowercase starting letters, second we also should avoid using underscores within method names. But what is even worse is that this prevents us from having a property that is named Item. What can we do now? Luckily the C# compiler knows an attribute, which can be used to change the default name.
The attribute is called IndexerNameAttribute and can be found (like all the other useful attributes) in the namespace System.Runtime.CompilerServices. Let's see how this could look like:
class MyClass
{
[IndexerName("MyIndexer")]
public int this[int index]
{
get { return index; }
}
public string Item
{
get { return "Test"; }
}
}
This naming does not have any direct consequences for our code. If we would use method names like get_Item as a search in reflection, then we would not find the indexer in this case. This is just another hint, that one should always carefully think about the possibilities when using reflection and inserting strings to find specific methods. Other criteria should to be considered as well, just to stay as bulletproof as possible.
Renaming has also another consequence: If we have more indexers within the same class, we need to place the exact same attribute on them as well. C# does not allows us to name different indexers differently. Each indexer within the same class needs to have the same reflection name.
→ Example code indexer.linq
Avoid boxing
Most performance problems rise with too many allocations being done. A close study of a given code might often reveal unnecessary allocations, especially those with boxing / unboxing. Quite often those boxing / unboxing operations are not as obvious as in the following code:
var number = 4; //number stored as an integer - no boxing
object count = 3; //count is an object and 3 is an integer, this will be boxed
When we look at the generated MSIL we will see that the box operation will bring in some overhead:
IL_0000: ldc.i4.3
IL_0001: box System.Int32
IL_0006: stloc.0 // count
Assigning the cast back to an integer variable called icount will require the unboxing operation. It is very likely that a box operation will have at least one unbox counterpart.
This is how it looks in the MSIL:
IL_0007: ldloc.0 // count
IL_0008: unbox.any System.Int32
IL_000D: stloc.1 // icount
However, sometimes this is not as obvious. A famous example is string concatination. Here we might use something like the following:
var a = 3;
var b = "Some string";
var c = a + b;
Problem: The problem with the code above is, that it is not using an overload of the String.Concat() method that supports two strings. The used overload does only support two objects. Therefore the first argument, an integer, will have to be boxed to an object - ouch! Needless to say, that there is a simple solution to this problem:
var a = 3;
var b = "Some string";
var c = a.ToString() + b;
This is also the problem that we can run into with our own method overloads. Let's consider the following problem: We have an interface and a structure that implements this interface. Of course we want to encourage a low-coupling by minimizing the requirements that a method has in terms of its input parameters. So we will design our system as follows:
interface IRun
{
void Run();
}
struct TestRun : IRun
{
public void Run()
{
"I am running ...".Dump();
}
}
void ExecuteRun(IRun runable)
{
runable.Run();
}
Obviously this seems to be really good code, doesn't it? But this code runs into the same problem as before with the string concatination. But how can we support structures in such a context? Is there a way to do this?
Solution: Generics is quite powerful, however, doing it with type-safety and intelli-sense in mind is quite difficult. Therefore C# introduces the concept of constraints, which comes in very handy for this problem. Instead of writing the method as before, we will allow copies of the same method. These copies will be generated by the C# compiler, for every type that implements our interface and uses this method.
The code could look like the following:
void ExecuteRun<T>(T runable) where T : IRun
{
runable.Run();
}
So while this solution works great for both, classes and structures, the solution above works only for classes. In the upper code structures will be boxed, which results in some overhead that might be unwanted if we search for an optimum of performance.
→ Example code boxing.linq
Points of Interest
While some of the tips are certainly only useful a couple of times in the life of a programmer (at least for the average one), others are real life savers. I consider the possibilities that are available by using extension methods one of the greatest achievements of C#.
Some of those tips are highly debatable, especially the section about sealed. My opinion in this matter seems to be formed. Sealing is great, but you should have a reason to do it. If you don't know if you should do it, then you probably should not do it. In the end one can certainly tell that API / library writers should think about this more than others. For somebody writing an application, I could recommend "Don't think about it, just skip it".
References
The following list contains some references to tricks found in this article, or general reading. Some of the links might also contain other tricks, that I found too obvious or not very useful, however, they might still be interesting for you.
- 8 things you probably did not know about C#
- StackOverflow: Hidden features of C#?
- 10 C# keywords you shouldn't use
- 6 more things developers should not do
- Undocumented C# types and keywords
- StackOverflow: RealProxy lets you create your own proxies for existing types
- StackOverflow: Avoid boxing by using generics
- Rambling on the sealed keyword
- StackOverflow: Why are sealed types faster?
- StackOverflow: Most useful attributes
- Creating proxies with the RealProxy
History
- v1.0.0 | Initial Release | 08.12.2013
- v1.0.1 | Improved StructLayout tip | 09.12.2013