Table of Contents
- Introduction
- Background - What are lambda expressions?
- Performance benchmarks
- Behind the curtain - MSIL
- JavaScript patterns with C#
- Useful scenarios
- Lambda patterns
- Using the code
- Points of interest
Introduction
Lambda expressions are a powerful way to make code more dynamic, easier to extend and also faster (see this article if you want to know: why!). They can be also used to reduce potential errors and make use of static typing and intellisense as well as the superior IDE of Visual Studio.
Lambda expressions have been introduced with the .NET-Framework 3.5 and C# 3 and have played an important part together with technologies like LINQ or a lot of the techniques behind ASP.NET MVC. If you think about the implementation of various controls in ASP.NET MVC you'll find out that most of the magic is actually covered by using lambda expressions. Using one of the Html extension method together with a lambda expression will make use of the model you have actually created in the background.
In this article I'll try to cover the following things:
- A brief introduction - what are lambda expressions exactly and why do they differ from anonymous methods (which we had before!)
- A closer look at the performance of lambda expressions - are there scenarios where we gain or lose performance against standard methods
- A really close look - how are lambda expressions handled in MSIL code
- A few patterns from the JavaScript world ported to C#
- Scenarios where lambda expressions excel - either performance-wise or out of pure comfort
- Some new patterns that I've come up with (maybe someone else did also come up with those - but that has been behind my knowledge)
So if you expect a beginner's tutorial here I will probably disappoint you, unless you are a really advanced and smart beginner. Needless to say I am not such a guy, which is why I want to warn you: for this article you'll need some advanced knowledge of C# and should know your way around this language.
What you can expect is an article that tries to explain some things. The article will also investigate some (at least for me) interesting questions. In the end I will present some practical examples and patterns that can be used on some occasions. I've found out that lambda expressions can simplify so many scenarios that writing down explicit patterns could be useful.
Background - What are lambda expressions?
In the first version of C# the construct of delegates has been introduced. This concept has been integrated to make passing functions possible. In a sense a delegate is a strongly typed (and managed) function pointer. A delegate can be much more (of course), but in essance that is what you get out. The problem was that passing a function required quite a lot of steps (usually):
- Writing the delegate (like a class), which includes specifying the return and argument types.
- Using the delegate as the type in the method that should receive some function with the signature that is described by the delegate.
- Creating an instance of the delegate with the specific function to be passed by this delegate type.
If this sounds complicated to you - it should be, because essentially it was (well, its not rocket science, but a lot more code than you would expect). Therefore step number 3 is usually not required and the C# compiler does the delegate creation for you. Still step 1 and 2 are mendatory!
Luckily C# 2 came with generics. Now we could write generic classes, methods and more important: generic delegates! However, it took until the .NET-Framework 3.5 until somebody at Microsoft realized that there are actually just 2 generic delegates (with some "overloads") required to cover 99% of the delegate use-cases:
Actionwithout any input arguments (no input and no output) and the generic overloadsAction<T1, ..., T16>, which take 1 to 16 types as parameters (no output), as well asFunc<T1, ..., T16, Tout>, which take 0 to 16 types as input parameters and 1 output parameter
While Action (and the corresponding generics) does return void (i.e. this is really just an action, which executes something), Func actually returns something which is of the last type that is specified. With those 2 delegates (and their overloads) we can really skip the first step in most times. Step 2 is still required, but just uses Action and Func.
So what if I just want to run some code? This issue has been attacked in C# 2. In this version you could create delegate funtctions, which are anonymous functions. However, the syntax never got popular. A very simple example of such an anonymous method looks like the following:
Func<double, double> square = delegate (double x) {
return x * x;
}
So let's improve this syntax and extend the possibilities. Welcome to lambda expression country! First of all where does this name come from? The name is actually derived from the lambda calculus in mathematics, which basically just states what is really required to express a function. More precisely it is a formal system in mathematical logic for expressing computation by way of variable binding and substitution. So basically we have between 0 and N input arguments and one return value. In our programming language we can also have no return value (void).
Let's have a look at some example lambda expressions:
//The compiler cannot resolve this, which makes using var impossible! Therefore we need to specify the type
Action dummyLambda = () => { Console.WriteLine("Hallo World from a Lambda expression!"); };
//Can be used as with double y = square(25);
Func<double, double> square = x => x * x;
//Can be used as with double z = product(9, 5);
Func<double, double, double> product = (x, y) => x * y;
//Can be used as with printProduct(9, 5);
Action<double, double> printProduct = (x, y) => { Console.WriteLine(x * y); };
//Can be used as with var sum = dotProduct(new double[] { 1, 2, 3 }, new double[] { 4, 5, 6 });
Func<double[], double[], double> dotProduct = (x, y) => {
var dim = Math.Min(x.Length, y.Length);
var sum = 0.0;
for(var i = 0; i != dim; i++)
sum += x[i] + y[i];
return sum;
};
//Can be used as with var result = matrixVectorProductAsync(...);
Func<double[,], double[], Task<double[]>> matrixVectorProductAsync = async (x, y) => {
var sum = 0.0;
/* do some stuff using await ... */
return sum;
};
What we learn directly from those statements:
- If we have only one argument, then we can omit the round brackets
() - If we only have one statement and want to return this, then we can omit the curly brackets
{}and skip thereturnkeyword - We can state that our lambda expressions can be executed asynchronous - just add the
asynckeyword as with usual methods - The
varstatement cannot be used in most cases - only in very special cases
Needless to say we could use var a lot more often (like always) if we would actually specify the parameter types. This is optional and usually not done (because the types can be resolved from the delegate type that we are using in the assignment), but it is possible. Consider the following examples:
var square = (double x) => x * x;
var stringLengthSquare = (string s) => s.Length * s.Length;
var squareAndOutput = (decimal x, string s) => {
var sqz = x * x;
Console.WriteLine("Information by {0}: the square of {1} is {2}.", s, x, sqz);
};
Now we know most of the basic stuff, but there are a few more things which are really cool about lambda expressions (and make them SO useful in many cases). First of all consider this code snippet:
var a = 5;
var multiplyWith = x => x * a;
var result1 = multiplyWith(10); //50
a = 10;
var result2 = multiplyWith(10); //100
Ah okay! So you can use other variables in the upper scope. That's not so special you would say. But I say this is much more special than you might think, because those are real captured variables, which makes our lambda expression a so called closure. Consider the following case:
void DoSomeStuff()
{
var coeff = 10;
var compute = (int x) => coeff * x;
var modifier = () => {
coeff = 5;
};
var result1 = DoMoreStuff(compute);
ModifyStuff(modifier);
s
var result2 = DoMoreStuff(compute);
}
int DoMoreStuff(Action<int> computer)
{
return computer(5);
}
void ModifyStuff(Action modifier)
{
modifier();
}
What's happening here? First we are creating a local variable and two lambdas in that scope. The first lambda should show that it is also possible to access local variables in other local scopes. This is actually quite impressive already. This means we are protecting a variable but still can access it within the other method. It does not matter if the other method is defined within this or in another class.
The second lambda should demonstrate that a lambda expression is also able to modify the upper scope variables. This means we can actually modify our local variables from other methods, by just passing a lambda that has been created in the corresponding scope. Therfore I consider closures a really mighty concept that (like parallel programming) could lead to unexpected results (similar, but if we follow our code not as unexpected as race conditions in parallel programing). To show one scenario with unexpected results we could do the following:
var buttons = new Button[10];
for(var i = 0; i < buttons.Length; i++)
{
var button = new Button();
button.Text = (i + 1) + ". Button - Click for Index!";
button.OnClick += (s, e) => { Messagebox.Show(i.ToString()); };
buttons[i] = button;
}
//What happens if we click ANY button?!
This is a tricky question that I usually ask my students in my JavaScript lecture. About 95% of the students would instantly say "Button 0 shows 0, Button 1 shows 1, ...". But some students already spot the trick and since the whole part of the lecture is about closures and functions it is obvious that there is a trick. The result is: Every button is showing 10!
The local scoped variable called i has changed its value and must have the value of buttons.Length, because obviously we already left the for-loop. There is an easy way around this mess (in this case). Just do the following with the body of the for-loop:
var button = new Button();
var index = i;
button.Text = (i + 1) + ". Button - Click for Index!";
button.OnClick += (s, e) => { Messagebox.Show(index.ToString()); };
buttons[i] = button;
This solves everything, but this variable index is a value type and therefore makes a copy to the more "global" (upper scoped) variable i.
The last topic of this advanced introduction is the possibility of having so called expression trees. This is only possible with lambda expressions and is responsible for the magic that is happening in ASP.NET MVC with the Html extension methods. The key question is: How can the target method find out
- what the name of the variable I am passing in is?
- what the structure of the body I am using is?
- what kind of types I am using within my body?
Now a Expression actually solves this problem. It allows us to dig our way through the compiler generated expression tree. Additionally we can execute the given function as with the usual Func or Action delegates. It also allows us to interpret the lambda expression later (at runtime).
Let's have a look at an example about how to use the objects of type Expression:
Expression<Func<MyModel, int>> expr = model => model.MyProperty;
var member = expr.Body as MemberExpression;
var propertyName = memberExpression.Member.Name; //only execute if member != null ...
This is the most simple example regarding the usage of such expressions. The principle is quite straight forward: By forming an object of type Expression the compiler generates meta information about the generated parse tree. This parse tree contains all relevant information like parameters (names, types, ...) and the method body.
The method body contains the whole parse tree. There we have access to operators, operands as well as complete statements and (most importantly) the return name and type. The name of the return variable could be null as well. However, most of the time one will be interested in expressions like the one above. This is also similar to the way that ASP.NET MVC handles the Expression type - to get the name of the parameter to use. The advantage for the programmer is obviously that he cannot misspell the name of the property, since every misspelling results in a compilation error.
Remark In the scenario where the programmer is just interested in the name of the calling property, there is a much simpler (and more elegant) solution. The special parameter attribute CallerMemberName can be used to get the name of the calling method or property. The field is automatically filled out by the compiler. Therefore if we are just interested in getting to know the name (without more type information etc.), we would just write code like the example method below (which returns the name of the method that just called the WhatsMyName() method).
string WhatsMyName([CallerMemberName] string callingName = null)
{
return callingName;
}
Performance of lambda expressions
A big question is: How fast are lambda expressions? Well, first we expect them to perform about as fast as regular functions, since they are compiler generated as well. In the next section we will see that the MSIL generated for lambda expressions is not that different to regular functions.
One of the most interesting discussions will be if lambda expressions will closures will perform as fast as methods with global variables. The really interesting region will be if the number of available variables in the local scope will matter.
Let's have a look at the code used for performing some benchmarks. All in all we are having a look at 4 different benchmarks, which should give us enough evidence to see differences between normal functions and lambda expressions.
using System;
using System.Collections.Generic;
using System.Diagnostics;
namespace LambdaTests
{
class StandardBenchmark : Benchmark
{
const int LENGTH = 100000;
static double[] A;
static double[] B;
static void Init()
{
var r = new Random();
A = new double[LENGTH];
B = new double[LENGTH];
for (var i = 0; i < LENGTH; i++)
{
A[i] = r.NextDouble();
B[i] = r.NextDouble();
}
}
static long LambdaBenchmark()
{
Func<double> Perform = () =>
{
var sum = 0.0;
for (var i = 0; i < LENGTH; i++)
sum += A[i] * B[i];
return sum;
};
var iterations = new double[100];
var timing = new Stopwatch();
timing.Start();
for (var j = 0; j < iterations.Length; j++)
iterations[j] = Perform();
timing.Stop();
Console.WriteLine("Time for Lambda-Benchmark: \t {0}ms", timing.ElapsedMilliseconds);
return timing.ElapsedMilliseconds;
}
static long NormalBenchmark()
{
var iterations = new double[100];
var timing = new Stopwatch();
timing.Start();
for (var j = 0; j < iterations.Length; j++)
iterations[j] = NormalPerform();
timing.Stop();
Console.WriteLine("Time for Normal-Benchmark: \t {0}ms", timing.ElapsedMilliseconds);
return timing.ElapsedMilliseconds;
}
static double NormalPerform()
{
var sum = 0.0;
for (var i = 0; i < LENGTH; i++)
sum += A[i] * B[i];
return sum;
}
}
}
We could write this code much better using lambda expressions (which then take the measurement of an arbitrary method that is passed using the callback pattern, as we will find out). The reason for not doing this is to not spoil the final result. So here we are with essentially three methods. One that is called for the lambda test and one that is called for normal test. The third methods is then invoked within the normal test. The missing fourth methods is our lambda expression, which will be created in the first method. The computation does not matter, we just pick random numbers to avoid any compiler optimizations in this area. In the end we are just interested in the difference between normal methods and lambda expressions.
If we run those benchmarks we will see that lambda expressions do usually not perform worse than usual methods. One surprise might be that lambda expressions actually can actually perform slightly better than usual functions. However, this is certainly not true in the case of having closures, i.e. captures variables. This just means that one should not hesitate to use lambda expressions regularly. But we should think carefully about the performance losses we might get when using closures. In such scenarios we will usually lose a little bit of performance, which might still be quite OK. The loss is created for several reasons as we will explore in the next section.
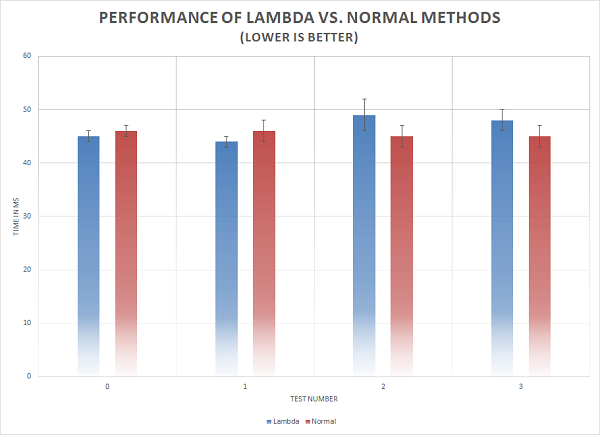
The plain data for our benchmarks is shown in table below:
| Test | Lambda [ms] | Normal [ms] |
|---|---|---|
| 0 | 45+-1 | 46+-1 |
| 1 | 44+-1 | 46+-2 |
| 2 | 49+-3 | 45+-2 |
| 3 | 48+-2 | 45+-2 |
The plots corresponding to this data are displayed below. We can see that usual functions and lambda expressions are performing within the same limits, i.e. there is no performance loss when using lambda expressions.
Behind the curtain - MSIL
Using the famous tool LINQPad we can have a close look at the MSIL without any burden. A screenshot of investigating the IL by using LINQPad is shown below.
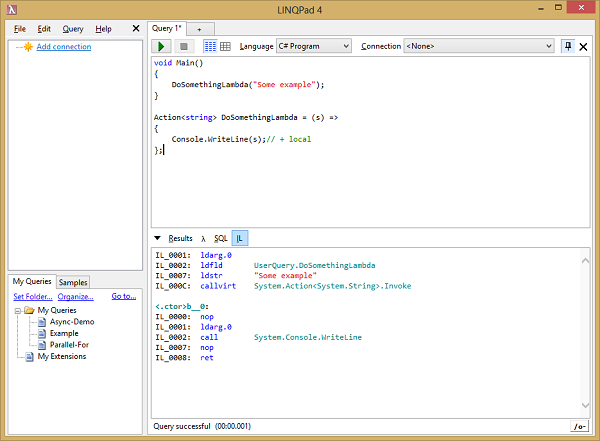
We will have a look at three examples. Let's start off with the first one. The lambda expression looks like:
Action<string> DoSomethingLambda = (s) =>
{
Console.WriteLine(s);// + local
};
The corresponding method has the following code:
void DoSomethingNormal(string s)
{
Console.WriteLine(s);
}
Those two codes result in the following two snippets of MSIL code:
DoSomethingNormal:
IL_0000: nop
IL_0001: ldarg.1
IL_0002: call System.Console.WriteLine
IL_0007: nop
IL_0008: ret
<Main>b__0:
IL_0000: nop
IL_0001: ldarg.0
IL_0002: call System.Console.WriteLine
IL_0007: nop
IL_0008: ret
The big difference here is the naming and usage of the method, not the declaration. The declaration is actually the same. The compiler creates a new method in the local class and inferes the usage of this method. This is nothing new - it is just a matter of convinience that we can use lambda expressions like this. From the MSIL view we are doing the same in both cases; namely invoking a method within the current object.
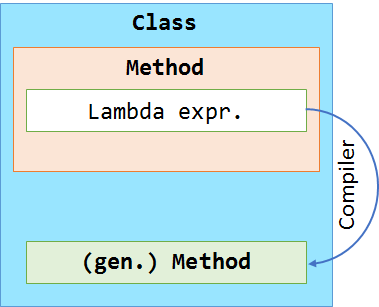
We could put this observation into a little diagram to illustrate the modification done by the compiler. In the picture below we see that the compiler actually moves the lambda expression to become a fixed method.
The second example shows the real magic of lambda expressions. In this example we are either using a (normal) method with global variables or a lambda expressions with captured variables. The code reads as follows:
void Main()
{
int local = 5;
Action<string> DoSomethingLambda = (s) => {
Console.WriteLine(s + local);
};
global = local;
DoSomethingLambda("Test 1");
DoSomethingNormal("Test 2");
}
int global;
void DoSomethingNormal(string s)
{
Console.WriteLine(s + global);
}
Now there is nothing unusual here. The key question is: How are lambda expressions resolved from the compiler?
IL_0000: newobj UserQuery+<>c__DisplayClass1..ctor
IL_0005: stloc.1
IL_0006: nop
IL_0007: ldloc.1
IL_0008: ldc.i4.5
IL_0009: stfld UserQuery+<>c__DisplayClass1.local
IL_000E: ldloc.1
IL_000F: ldftn UserQuery+<>c__DisplayClass1.<Main>b__0
IL_0015: newobj System.Action<System.String>..ctor
IL_001A: stloc.0
IL_001B: ldarg.0
IL_001C: ldloc.1
IL_001D: ldfld UserQuery+<>c__DisplayClass1.local
IL_0022: stfld UserQuery.global
IL_0027: ldloc.0
IL_0028: ldstr "Test 1"
IL_002D: callvirt System.Action<System.String>.Invoke
IL_0032: nop
IL_0033: ldarg.0
IL_0034: ldstr "Test 2"
IL_0039: call UserQuery.DoSomethingNormal
IL_003E: nop
DoSomethingNormal:
IL_0000: nop
IL_0001: ldarg.1
IL_0002: ldarg.0
IL_0003: ldfld UserQuery.global
IL_0008: box System.Int32
IL_000D: call System.String.Concat
IL_0012: call System.Console.WriteLine
IL_0017: nop
IL_0018: ret
<>c__DisplayClass1.<Main>b__0:
IL_0000: nop
IL_0001: ldarg.1
IL_0002: ldarg.0
IL_0003: ldfld UserQuery+<>c__DisplayClass1.local
IL_0008: box System.Int32
IL_000D: call System.String.Concat
IL_0012: call System.Console.WriteLine
IL_0017: nop
IL_0018: ret
<>c__DisplayClass1..ctor:
IL_0000: ldarg.0
IL_0001: call System.Object..ctor
IL_0006: ret
Again both functions are equal from the statements they call. The same mechanism has been applied again, namely the compiler generated a name for the function and placed it somewhere in the code. The big difference now is that the compiler also generated a class, where the compiler generated function (our lambda expression) has been placed in. An instance of this class is generated in the function, where we are (originally) creating the lambda expression. What's the purpose of this class? It gives a global scope to the variables, which have been used as captured variables previously. With this trick, the lambda expression has access to the local scoped variables (because from the MSIL perspective, they are just global variables sitting in a class instance).
All variables are therefore assigned and read from the instance of the freshly generated class. This solves the problem of having references between variables (there has just to be one additional reference to the class - but that's it!). The compiler is also smart enough to just place those variables in the class, which have been used as captured variables. Therefore we could have expected to have no performance issues when using lambda expressions. However, a warning is required that this behavior can enhance memory leaks due to still referenced lambda expressions. As lang as the function lives, the scope is still alive as well (this should have been obvious before - but now we do see the reason!).
Like before we will also put this into some nice little diagram. Here we see that in the case of closures not only the method is moved, but also the captured variables. All the moved objects will then be placed in a compiler generated class. Therefore we end up with instantiating a new object from a yet unknown class.
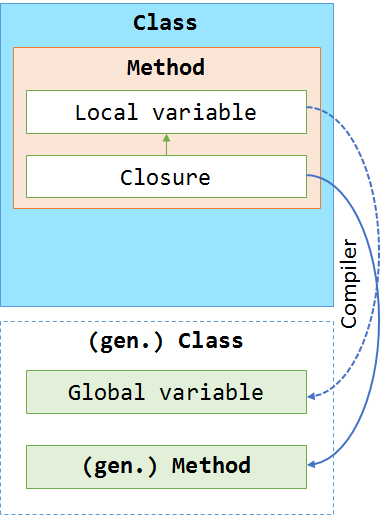
Porting some popular JavaScript patterns
One of the advantages of using (or knowing) JavaScript is the superior usage of functions. In JavaScript functions are just objects and can have properties assigned to them as well. In C# we cannot do everything that we can do in JavaScript, but we can do some things. One of the reasons for this is that JavaScript gives scope to variables within functions. Therefore one has to create (mostly anonymous) functions to localize variables. In C# we create scopes by using blocks, i.e. using curly brackets.
Of course in a way, functions do also give scope in C#. By using a lambda expression we are required to use curly brackets (i.e. create a new scope) for creating a variable within a lambda expression. However, additionally we can also create scopes locally.
Let's have a look at some of the most useful JavaScript patterns that are now possible in C# by using lambda expressions.
Callback Pattern
This pattern is an old one. Actually the callback pattern has been used since the first version of the .NET-Framework, but in a slightly different way. Now the deal is that lambda expression can be used as closures, i.e. capturing local variables, which is an interesting feature that allows us to write code like the following:
void CreateTextBox()
{
var tb = new TextBox();
tb.IsReadOnly = true;
tb.Text = "Please wait ...";
DoSomeStuff(() => {
tb.Text = string.Empty;
tb.IsReadOnly = false;
});
}
void DoSomeStuff(Action callback)
{
// Do some stuff - asynchronous would be helpful ...
callback();
}
This whole pattern is nothing new for people who are coming from JavaScript. Here we usually tend to use this pattern a lot, since it is really useful and since we can use the parameter as event handler for AJAX related events (oncompleted, or onsuccess etc.), as well as other helpers. If you are using LINQ, then you also use part of the callback pattern, since for example the LINQ where will callback your query in every iteration. This is just one example when callback functions are useful. In the .NET-world usually events are the preferred way of doing events (as the name suggests), which is something like a callback on steroids. The reasons for this are two-fold, having a special keyword and type-pattern (2 parameters: sender and arguments, where sender is usually of type object (most general type) and arguments inherits from EventArgs), as well as having the opportunity to more than just one method to be invoked by using the += (add) and -= (remove) operators.
Returning Functions
As with usual functions, lambda expressions can also return a function pointer (delegate instance). This means that we can use a lambda expression to create and return a lambda expression (or just a delegate instance to an already defined method). There are plenty of scenarios where such a behavior might be helpful. First let's have a look at some example code:
Func<string, string> SayMyName(string language)
{
switch(language.ToLower())
{
case "fr":
return name => {
return "Je m'appelle " + name + ".";
};
case "de":
return name => {
return "Mein Name ist " + name + ".";
};
default:
return name => {
return "My name is " + name + ".";
};
}
}
void Main()
{
var lang = "de";
//Get language - e.g. by current OS settings
var smn = SayMyName(lang);
var name = Console.ReadLine();
var sentence = smn(name);
Console.WriteLine(sentence);
}
The code could have been shorter in this case. We could have also avoided a default return value by just throwing an exception if the requested language has not been found. However, for illustration purposes this example should show that this is kind of a function factory. Another way to do this would be involving a Hashtable or the even better (due to static typing) Dictionary<K, V> type.
static class Translations
{
static readonly Dictionary<string, Func<string, string>> smnFunctions = new Dictionary<string, Func<string, string>>();
static Translations()
{
smnFunctions.Add("fr", name => "Je m'appelle " + name + ".");
smnFunctions.Add("de", name => "Mein Name ist " + name + ".");
smnFunctions.Add("en", name => "My name is " + name + ".");
}
public static Func<string, string> GetSayMyName(string language)
{
//Check if the language is available has been omitted on purpose
return smnFunctions[language];
}
}
//Now it is sufficient to call Translations.GetSayMyName("de") to get the function with the German translation.
Even though this seems like over-engineered it might be the best way to do such function factories. After all this way is very easy to extend and can be used in a lot of scenarios. This pattern in combination with reflection can make most programming codes a lot more flexible, easier to maintain and more robust to extend. How such a pattern works is shown in the next picture.
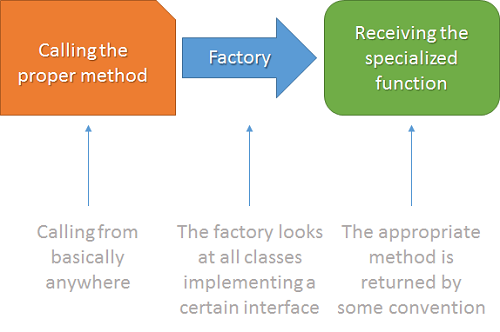
Self-Defining Functions
The self-defining function pattern is a common trick in JavaScript and could be used to gain performance (and reliability) in any code. The main idea behind this pattern is that a function that has been set as a property (i.e. we only have a function pointer set on a variable) can be exchanged with another function very easily. Let's have a look what that means exactly:
class SomeClass
{
public Func<int> NextPrime
{
get;
private set;
}
int prime;
public SomeClass
{
NextPrime = () => {
prime = 2;
NextPrime = () => {
//Algorithm to determine next - starting at prime
//Set prime
return prime;
};
return prime;
}
}
}
What is done here? Well, in the first case we just get the first prime number, which is 2. Since this has been trivial, we can adjust our algorithm to exclude all even numbers by default. This will certainly speed up our algorithm, but we will still get 2 as the starting prime number. We will not have to see if we already performed a query on the NextPrime() function, since the function defines itself once the trivial case (2) has been returned. This way we save resources and can optimize our algorithm in the more interesting region (all numbers, which are greater than 2).
We already see that this can be used to gain performance as well. Let's consider the following example:
Action<int> loopBody = i => {
if(i == 1000)
loopBody = /* set to the body for the rest of the operations */;
/* body for the first 1000 iterations */
};
for(int j = 0; j < 10000000; j++)
loopBody(j);
Here we basically just have two distinct regions - one for the first 1000 iterations and another for the 9999000 remaining iterations. Usually we would need a condition to differ between the two. This would be unnecessary overhead in most cases, which is why we use a self-defining function to change itself after the smaller region has been executed.
Immediately-Invoked Function Expression
In JavaScript immediately-invoked function expressions (so called IIFEs) are quite common. The reason for this is that unlike in C# curly brackets do not give scope to form new local variables. Therefore one would pollute the global (that is mostly the window object) object with variables. This is unwanted due to many reasons.
The solution is quite simple: While curly brackets do not give scope, functions do. Therefore variables defined within any function are restricted to this function (and its children). Since usually JavaScript users want those functions to be executed directly it would be a waste of variables and statement lines to first assign them a name and then execute them. Another reason for that this execution is required only once.
In C# we can easily write such functions as well. Here we also do get a new scope, but this should not be our main focus, since we can easily create a new scope anywhere we want to. Let's have a look at some example code:
(() => {
// Do Something here!
})();
This code can be resolved easily. However, if we want to do something with parameters, then we will need to specify their types. Let's have an example of something that passes some arguments to the IIFE.
((string s, int no) => {
// Do Something here!
})("Example", 8);
This seems like too many lines for gaining nothing. However, we could combine this pattern to use the async keyword. Let's view an example:
await (async (string s, int no) => {
// Do Something here async using Tasks!
})("Example", 8);
//Continue here after the task has been finished
Now there might be one or the other usage as an async-wrapper or similar.
Immediate Object Initialization
Quite close related is the immediate object initialization. The reason why I am including this pattern in an article about lambda expressions is that anonymous objects are quite powerful as they can contain more than just simple types. One thing that they could include are also lambda expressions. This is why there is something that can be discussed in the area of lambda expressions.
//Create anonymous object
var person = new {
Name = "Florian",
Age = 28,
Ask = (string question) => {
Console.WriteLine("The answer to `" + question + "` is certainly 42!");
}
};
//Execute function
person.Ask("Why are you doing this?");
If you want to run this pattern, then you will most probably see an exception (at least I am seeing one). The mysterious reason is that lambda expressions cannot be assigned to anonymous objects. If that does not make sense to you, then we are sitting in the same boat. Luckily for us everything the compiler wants to tell us is: "Dude I do not know what kind of delegate I should create for this lambda expression!". In this case it is easy to help the compiler. Just use the following code instead:
var person = new {
Name = "Florian",
Age = 28,
Ask = (Action<string>)((string question) => {
Console.WriteLine("The answer to `" + question + "` is certainly 42!");
})
};
One of the questions that certainly arises is: In what scope does the function (in this case Ask) live? The answer is that it lives in the scope of the class that creates the anonymous object or in its own scope if it uses captured variables. Therefore the compiler still creates an anonymous object (which involves laying out the meta information for a compiler-generated class, instantiating a new object with the class information behind and using it), but is just setting the property Ask with the delegate object that refers to the position of our created lambda expression.
Caution You should avoid using this pattern when you actually want to access any of the properties of the anonymous object inside any of the lambda expressions you are directly setting to the anonymous object. The reason is the following: The C# compiler requires every object to be declared before you can actually use them. In this case the usage would be certainly after the declaration; but how should the compiler know? From his point of view the access is simultaneous with the declaration, hence the variable person has not been declared yet.
There is one way out of this hell (actually there are more ways, but in my opinion this is the most elegant...). Consider the following code:
dynamic person = null;
person = new {
Name = "Florian",
Age = 28,
Ask = (Action<string>)((string question) => {
Console.WriteLine("The answer to `" + question + "` is certainly 42! My age is " + person.Age + ".");
})
};
//Execute function
person.Ask("Why are you doing this?");
Now we declare it before. We could have done the same thing by stating that person is of type object, but in this case we would require reflection (or some nice wrappers) to access the properties of the anonymous object. In this case we are relying on the DLR, which results in the nicest wrapper available for such things. Now the code is very JavaScript-ish and I do not knnow if this is a good thing or not ... (that's why there is a caution for this remark!).
Init-Time Branching
This pattern is actually quite closely related to the self-defining function. The only difference is, that in this case the function is not defining itself, but other functions. This is obviously only possible, if the other functions are not defined in a classic way, but over properties (i.e. member variables).
The pattern is also known under the name load-time branching and is essentially an optimization pattern. This pattern has been created to avoid permanent usage of switch-case or if-else etc. control structures. So in a way one could say that this pattern is creating roads to connect certain branches of the code permanently.
Let's consider the following example:
public Action AutoSave { get; private set; }
public void ReadSettings(Settings settings)
{
/* Read some settings of the user */
if(settings.EnableAutoSave)
AutoSave = () => { /* Perform Auto Save */ };
else
AutoSave = () => { }; //Just do nothing!
}
Here we are doing two things. First we have one method to read out the users settings (handling some arbitrary Settings class). If we find that the user has enabled the auto saving, then we set the full code to the property. Otherwise we are just placing a dummy method on this location. Therefore we can always just call the AutoSave() property and invoke it - we will always do what has been set. There is no need to check the settings again or something similar. We also do not need to save this one particular setting in a boolean variable, since the corresponding function has been set dynamically.
One might think that this is not a huge performance gain, but this is just one small example. In a very complex code this could actually save some time - especially if the scenarios are getting more complex and when the dynamically set methods will be called within (huge) loops.
Also (and I consider this the main reason) this code is probably easier to maintain (if one knows about this pattern) and easier to read. Instead of unnecessery control sequences one can focus on what's important: calling the auto save routine for instance.
In JavaScript such load-time branching pattern has been used the most in combination with feature (or browser) detection. Not to mention that browser detection is in fact evil and should not be done on any website, feature detection is indeed quite useful and is used best in combination with this pattern. This is also the way that (as an example) jQuery detects the right object to use for AJAX requests. Once it spots the XMLHttpRequest object within the browser, there is no chance that the underlyling browser will change in the middle of our script execution resulting in the need to deal with an ActiveX object.
Scenarios in which lambdas are super useful
Some of the patterns are more applicable than others. One really useful pattern is the self-defining function expression for initializing parts of some objects. Let's consider the following example:
We want to create an object that is able of performing some kind of lazy loading. This means that even though the object has been properly instantiated, we did not load all the required resources. One reason to avoid this is due to a massive IO operation (like a network transfer over the Internet) for obtaining the required data. We want to make sure that the data is as fresh as possible, when we start working with the data. Now there are certain ways to do this, and the most efficient would certainly be the way that the Entity Framework has solved this lazy loading scenario with LINQ. Here IQueryable<T> only stores the queries without having the underlying data. Once we require a result, not only the constructed query is executed, but the query is executed in the most efficient form, e.g. as an SQL query on the remote database server.
In our scenario we just want to differ between the two states. First we query, then everything should be prepared and queries should be performed on the loaded data.
class LazyLoad
{
public LazyLoad()
{
Search = query => {
var source = Database.SearchQuery(query);
Search = subquery => {
var filtered = source.Filter(subquery);
foreach(var result in filtered)
yield return result;
};
foreach(var result in source)
yield return result;
};
}
public Func<string, IEnumerable<ResultObject>> Search { get; private set; }
}
So we basically have two different kind of methods to be set here. The first one will pull the data out of the Database (or whatever this static class is doing), while the second one will filter the data that has been pulled out from the database. Once we have our result we will basically just work with the set of results from this first query. Of course one could also imagine to built in another method to reset the behavior of this class or other methods that would be useful for a productive code.
Another example is the init-time branching. Assume that we have an object that has one method called Perform(). This method will be used to invoke some code. This object that contains this method could be initialized (i.e.constructed) in three different ways:
- By passing the function to invoke (direct).
- By passing some object which contains the function to invoke (indirect).
- Or by passing the information of the first case in a serialized form.
Now we could save all those three states (along with the complete information given) as global variables. The invocation of the Perform() method would now have to look at the current state (either saved in an enumeration variable, or due to comparisons with null) and then determine the right way to be invoked. Finally the invocation could begin.
A much better way is to have the Perform() method as a property. This property can only be set within the object and is a delegate type. Now we can set the property directly in the corresponding constructor. Therefore we can omit the global variables and do not have to worry about in which way the object has been constructed. This performs better and has the advantage of being fixed, once constructed (as it should be).
A little bit of example code regarding this scenario:
class Example
{
public Action<object> Perform { get; private set; }
public Example(Action<object> methodToBeInvoked)
{
Perform = methodToBeInvoked;
}
//The interface is arbitrary as well
public Example(IHaveThatFunction mother)
{
//The passed object must have the method we are interested in
Perform = mother.TheCorrespondingFunction;
}
public Example(string methodSource)
{
//The Compile method is arbitrary and not part of .NET or C#
Perform = Compile(methodSource);
}
}
Even though this example seems to be constructed (pun intended) it can applied quite often, however, mostly with just the first two possible calls. Interesting scenarios rise in the topics of domain specific languages (DSL), compilers, to logging frameworks, data access layers and many many more. Usually there are many ways to finish the task, but a carefully and well-thought lambda expression might be the most elegant solution.
Thinking about one scenario where one would certainly benefit from having an immediately invoked function expression is in the area of functional programming. However, without going to deep into this topic I'll show another way to use IIFE in C#. The scenario I am showing is also a common one, but it will certainly not being used that often (and I believe that this is really OK that way, that it is not used in such scenarios).
Func<double, double> myfunc;
var firstValue = (myfunc = (x) => {
return 2.0 * x * x - 0.5 * x;
})(1);
var secondValue = myfunc(2);
//...
One can also use immediately invoked functions to prevent that certain (non-static) methods will be invoked more than once. This is then a combination of self-defining functions with init-time branching and IIFE.
Some new lambda focused design patterns
This section will introduce some patterns I've come up with that have lambda expressions in their core. I do not think that all of them are completely new, but at least I have not seen anyone putting a name tag on them. So I decided that I'll try to come up with some names that might be good or not (it will be a matter of taste). At least the names I'll pick try to be descriptive. I will also give a judgement if this pattern is useful, powerful or dangerous. To say something in advance: Most pattern are quite powerful, but might introduce potential bugs in your code. So handle with care!
Polymorphism completely in your hands
Lambda expressions can be used to create something like polymorphism (override) without using abstract or virtual (that does not mean that you cannot use those keywords). Consider the following code snippet:
class MyBaseClass
{
public Action SomeAction { get; protected set; }
public MyBaseClass()
{
SomeAction = () => {
//Do something!
};
}
}
Now nothing new here. We are creating a class, which is publishing a function (a lambda expression) over a property. This is again quite JavaScript-ish. The interesting part is that not only this class has the control to change the function that is exposed by the property, but also children of this class. Take a look at this code snippet:
class MyInheritedClass : MyBaseClass
{
public MyInheritedClass
{
SomeAction = () => {
//Do something different!
};
}
}
Aha! So we could actually just change the method (or the method that is set to the property to be more accurate) by abusing the protected access modifier. The disadvantage of this method is of course that we cannot directly access the parent's implementation. Here we are lacking the powers of base, since the base's property has the same value. If one really need's something like that, then I suggest the following *pattern*:
class MyBaseClass
{
public Action SomeAction { get; private set; }
Stack<Action> previousActions;
protected void AddSomeAction(Action newMethod)
{
previousActions.Push(SomeAction);
SomeAction = newMethod;
}
protected void RemoveSomeAction()
{
if(previousActions.Count == 0)
return;
SomeAction = previousActions.Pop();
}
public MyBaseClass()
{
previousActions = new Stack<Action>();
SomeAction = () => {
//Do something!
};
}
}
In this case the children have to go over the method AddSomeAction() to override the current set method. This method will then just push the currently set method to the stack of previous methods enabling us to restore any previous state.
My name for this pattern is Lambda Property Polymorphism Pattern (or short LP3). It basically describes the possibility of encapsulting any function in a property, which then can be set by derivatives of the base class. The stack is just an addition to this pattern, which does not change the patterns goal to use a property as the point of interaction.
Why this pattern? Well, there are several reasons. To start with: Because we can! But wait, this pattern can actually become quite handy if you start to use quite different kinds of properties. Suddenly the word "polymorphism" becomes a complete new meaning. But this will be a different pattern... Now I just want to point out that this pattern can in reality do things that have been thought to be impossible.
An example: You want (it is not recommended, but it would be the most elegant solution for your problem) to override a static method. Well, inheritence is not possible with static methods. The reason for this is quite simple: Inheritence just applies to instances, whereas static members are not bound to an instance. They are the same for all instances. This also implies a warning. The following pattern might not have the outcome you want to have, so only use it when you know what you are doing!
Here's some example code:
void Main()
{
var mother = HotDaughter.Activator().Message;
//mother = "I am the mother"
var create = new HotDaughter();
var daughter = HotDaughter.Activator().Message;
//daughter = "I am the daughter"
}
class CoolMother
{
public static Func<CoolMother> Activator { get; protected set; }
//We are only doing this to avoid NULL references!
static CoolMother()
{
Activator = () => new CoolMother();
}
public CoolMother()
{
//Message of every mother
Message = "I am the mother";
}
public string Message { get; protected set; }
}
class HotDaughter : CoolMother
{
public HotDaughter()
{
//Once this constructor has been "touched" we set the Activator ...
Activator = () => new HotDaughter();
//Message of every daughter
Message = "I am the daughter";
}
}
This is only a very simple and hopefully not totally misleading example. The things can become very complex in such a pattern, which is why I would always want to avoid it. Nevertheless it is possible (and it is also possible to construct all those static properties and functions in such a way, that you are still always getting the one in which you are interested in). A good solution regarding static polymorphism (yes, it is possible!) is not easy and requires some coding and should only be done if it really solves your problem without any additional headaches.
Simply request a function
One pattern I kind of introduced already (but I did not specify a name) is the Function Dictionary Pattern. The basic ingredients for this pattern are: a hashtable or dictionary that contains some kind of keys (usually strings, but depending on the situation it could be also a more specialized object, e.g. in YAMP I am using regular expressions), with a certain type of function for the values. The pattern also specifies a particular style of building the dictionary. This is actually required for the pattern, otherwise a simple switch-case in a function does the same job. Consider this example:
public Action GetFinalizer(string input)
{
switch
{
case "random":
return () => { /* ... */ };
case "dynamic":
return () => { /* ... */ };
default:
return () => { /* ... */ };
}
}
Where do we need a dictionary here? No where. Of course we could also do the following:
Dictionary<string, Action> finalizers;
public void BuildFinalizers()
{
finalizers = new Dictionary<string, Action>();
finalizers.Add("random", () => { /* ... */ });
finalizers.Add("dynamic", () => { /* ... */ });
}
public Action GetFinalizer(string input)
{
if(finalizers.ContainsKey(input))
return finalizers[input];
return () => { /* ... */ };
}
But wait - there is now no advantage to this pattern. Actually this pattern is far less efficient and required additional lines. But what we can do is to use reflection in order to "automate" the building process of the dictionary. And this way we might not be as efficient as with the switch-case statement, but we are robust in our code and require less maintenance in coding. This can be actually quite handy, if you think of a really large code, where you would need to add each function by hand to the switch-case block.
Let's have a look at a possible implementation. I usually prefer to add some kind of convention in order to pick the names for the keys of the dictionary. However, one can also think about choosing the value of a property of the picked class or the name of the method which fulfills a certain signature or requirement. In this example we are going for the one by convention.
static Dictionary<string, Action> finalizers;
//The method should be called by a static constructor or something similar
//The only requirement is that we built
public static void BuildFinalizers()
{
finalizers = new Dictionary<string, Action>();
//Get all types of the current (= where the code is contained) assembly
var types = Assembly.GetExecutingAssembly().GetTypes();
foreach(var type in types)
{
//We check if the class is of a certain type
if(type.IsSubclassOf(typeof(MyMotherClass)))
{
//Get the constructor
var m = type.GetConstructor(Type.EmptyTypes);
//If there is an empty constructor invoke it
if(m != null)
{
var instance = m.Invoke(null) as MyMotherClass;
//Apply the convention to get the name - in this case just we pretend it is as simple as
var name = type.Name.Remove("Mother");
//Name could be different, but let's just pretend the method is named MyMethod
var method = instance.MyMethod;
finalizers.Add(name, method);
}
}
}
}
public Action GetFinalizer(string input)
{
if(finalizers.ContainsKey(input))
return finalizers[input];
return () => { /* ... */ };
}
Now this looks a little bit better! Actually this pattern saved me a lot work. The best thing with this pattern is, however, the following: It enables you to write such nice plugins, and enable functionality across various libraries. Why is that? You can use this code to scan NEW (yet unknown) libraries for certain patterns and include them in your code. The functions from other libraries will be integrated within your code without any problem. All you have to do is the following:
//The start is the same
internal static void BuildInitialFinalizers()
{
finalizers = new Dictionary<string, Action>();
LoadPlugin(Assembly.GetExecutingAssembly());
}
public static void LoadPlugin(Assembly assembly)
{
//This line has changed
var types = assembly.GetTypes();
//The rest is identical! Perfectly refactored and obtained a new useful method
foreach(var type in types)
{
if(type.IsSubclassOf(typeof(MyMotherClass)))
{
var m = type.GetConstructor(Type.EmptyTypes);
if(m != null)
{
var instance = m.Invoke(null) as MyMotherClass;
var name = type.Name.Remove("Mother");
var method = instance.MyMethod;
finalizers.Add(name, method);
}
}
}
}
//The call is the same
Now (in our application) we just need a point to specify plugins and some function to handle those. In the end it will boil down to reading out the paths, trying to create the assembly object from the given paths and call the LoadPlugin() method with the obtained Assembly instance. And this is just one application of this pattern. I am using this pattern a lot, and I also tried to use it in JavaScript (there is no reflection built in, but if you look at my Mario5 article, then you'll probably see what I did there to create something similar).
Power up your attributes
Attributes are one of the greatest features of the C# language. Many things that could not be done that easily in C/C++ can be written in a few lines of C# code, just by using attributes. This pattern combines the features of attributes with lambda expressions. In the end this Functional Attribute Pattern will increase the possibilities and therefore the productivity of attributes even more.
Lambda expressions can be fairly helpful in combination with attributes, since we do not have to write specific classes for specific cases. I try to explain what I mean by a simple example. Let's consider a class with properties like the following:
class MyClass
{
public bool MyProperty
{
get;
set;
}
}
Now we want to do the following with any instance of this class: we want to be able to alter the property by some kind of domain specific language or scripting language. Therefore we want to be able to alter the value of the property without explicitely writing the code for it. Of course we will require some reflection for this. We will also require some attribute, since we need a way to specify if the value of this property can actually be changed by the user.
class MyClass
{
[NumberToBooleanConverter]
[StringToBooleanConverter]
public bool MyProperty
{
get;
set;
}
}
So we specified two kind of converters here. One would be sufficient to mark this property to be alterable by any user. We use two such attributes to give the user more possibilities. In this scenario a user could actually use a string to set the value (which will be converted to the boolean type) as well as a number (like 0 or 1).
How are the converters actually implemented? Let's view an example implementation in form of the StringToBooleanConverterAttribute class.
public class StringToBooleanConverterAttribute : ValueConverterAttribute
{
public StringToBooleanConverterAttribute()
: base(typeof(string), v => {
var str = (v as string ?? string.Empty).ToLower();
if (str == "on")
return true;
else if (str == "off")
return false;
throw new Exception("The only valid input arguments are [ on, off ]. You entered " + str + ".");
})
{
/* Nothing here on purpose */
}
}
public abstract class ValueConverterAttribute : Attribute
{
public ValueConverterAttribute(Type expected, Func>object, object> converter)
{
Converter = converter;
Expected = expected;
}
public ValueConverterAttribute(Type expected)
{
Expected = expected;
}
public Func<Value, object> Converter { get; set; }
public object Convert(object argument)
{
return Converter.Invoke(argument);
}
public bool CanConvertFrom(object argument)
{
return Expected.IsInstanceOfType(argument);
}
public Type Expected
{
get;
set;
}
public string Type
{
get { return Expected.Name; }
}
}
What are advantages of this pattern? Well, if attributes could take non-constant expressions as arguments (like delegates, i.e. lambda expressions would be possible), then we would certainly benefit much more from this pattern. This way, we only replace abstract methods with lambda expressions that will be passed in to the base class constructor.
More to come ...
This section will be updated with more patterns the next few days... So stay tuned!
Using the code
I've compiled a collection of some of the samples and made a list of the benchmarks. I've collected everything in a console project - so it should basically run on every platform (I mean Mono, .NET, Silverlight, ... you name it!) that supports C# up to version 3. My recommendation is that one should first try around with LINQPad. Most of the sample code here can be compiled directly within LINQPad. Some examples are very abstract and cannot be compiled without creating a proper scenario as described.
Nevertheless I hope that the code demonstrates some of the features I've mentioned in this article. I also hope that lambda expressions become as strongly used as interfaces are being used nowadays. Thinking back some years interfaces seemed like totally over-engineered with not so much use at all. Nowadays everyone's just talking about interfaces - "where's the implementation?" one might ask... Lambda expressions are so useful that the greatest extensions make them do work as they should. Could you imagine programming in C# without LINQ, ASP.NET MVC, Reactive Extensions, Tasks ... (your favorite framework?) the way you know and enjoy it?
Points of Interest
When I first saw the syntax for lambda expressions I somehow got frightend a bit. The syntax seemed complicated and not very useful. Now I completely reverted my opinion. I think the syntax is actually quite amazing (especially compared to the syntax that is present in C++11, but this is just a matter of taste). I also think that lambda expressions are a crucial part of the whole C# language.
Without this language feature I doubt that C# would have created such nice possibilites like ASP.NET MVC, lots of the MVVM frameworks, ... and not to mention LINQ! Of course all those technologies would have been possible as well, but not in such a clear and nicely useable way.
A personal note at the end. It's been one year that I am actively contributing to the CodeProject! This is my 16th article (this is great since I like integer powers of 2) and I am happy that so many people find some of my articles helpful. I hope that all of you will appreciate what is about to come in 2013, where I will probably focus on creating a bridge between C# and JavaScript (I leave it open to you to imagine what I mean by that - and no: its not one of those seen C# to JavaScript or MSIL to JavaScript transpilers).
That being said: I wish everyone a merry christmas and a happy new year 2013!
History
- v1.0.0 | Initial Release | 12.12.2012
- v1.1.0 | Added LP3 pattern | 14.12.2012
- v1.2.0 | Added FDP pattern | 19.12.2012
- v1.3.0 | Added FA pattern | 01.01.2013